There’s an interesting article on Fusion which describes how Campaign Grid is using analytics, broad data and cookies to help understand political sentiment.
Politics, Privacy and Business Intelligence
Leave a reply
There’s an interesting article on Fusion which describes how Campaign Grid is using analytics, broad data and cookies to help understand political sentiment.
The latest TDWI webinar was on embedded analytics. The speakers were Fern Halper, the director of TDWI research for advanced analytics, and Mark Gamble from OpenText. For those of you who hadn’t heard, Actuate was acquired by OpenText and is being rebranded but, according to Mark, will remain an independent division for now.
Ms. Halper’s main point is that embedded has a lot of different meanings for different audiences and that she wants to create a clear framework for understanding the terminology within the analytics space. She’s clear that what’s meant isn’t just into the mass market idea of wearable software, but that analytics can be embedded in specific applications, broader systems and, yes, devices such as mobile and wearable items.
Early in the presentation she presented a two axis image comparing structured and unstructured data combined with human and machine generated data. While I think the coloring should rotate, to emphasize that the difference between machine versus human generated information is a bigger issue than structured v unstructured, it’s a nice way of understanding some of the data streams.

That, however, was a definitional slide and discussion. The real mean of Fern Halper’s presentation was the framework she described to help understand the steps of embedding analytics.
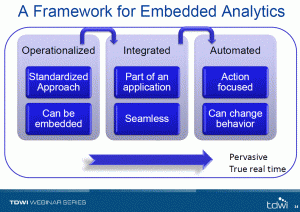
Operationalized analytics are those that are involved in the full process of decision making. For instance, a call center employee might be talking to a prospect whose finances are flagged as a question mark. That prospect must be sent to another person to process the decision based on analytics.
Integrated analytics are those that allow the call center operator to see the analysis and immediately make decisions based upon guidelines.
Automated analytics are those that provide the operator with a decision tree response based on analytics done behind the scenes.
The only issue I take with the framework is it doesn’t necessarily mean true real time. The example discussed shows that the integrated approach can be real time for what humans think of as real time within our own interactions. Meanwhile, real-time might not be a necessary component to some automated decisions. Real-time is a separate issue and I think Fern’s framework would be better served by eliminating that item.
Fern Halper followed the framework with the usual and interesting TDWI survey numbers. This time, the questions were focused on the adoption of analytics tied to the framework. The numbers showed the unsurprising fact that analytics adoption is still in its infancy. One of the great parts of TDWI’s numbers is they show the reality which contradicts the industry’s hype.
One set of numbers I’d like to see wasn’t included. The responses were only IT responses in general, who has started using what analytics. I would have loved to see one slide that clearly showed only the sub-segment of companies who are already using analytics tools and where those companies are within Ms. Halper’s framework. Are are the bleeding edge folks doing at moving through the framework to automated solutions?
The rest of the program was a fast presentation by Mark Gamble, pointing to OpenText’s (Actuate’s) main benefit claim of enterprise scalability and the other factors. One of the phrases I liked was his reference stating they “adhered to a low code methodology.” It’s nice to hear folks admitting that as much as we want to eliminate coding, some of that is still required. Honesty isn’t a negative in marketing and I liked that turn of phrase.
In the other direction, he mentioned there were over fourteen million downloads of BIRT and that the company “believes” they have over three million users. I’m not interested in belief but they don’t seem to have a clear figure on adoption.
The main problem I had was the demo. Mark showed experimental work positing to show live acquisition of basic automotive information such as speed and RPM displayed on a computer, phone and watch. It was not only not a business case but one that seemed to go back to the misunderstanding about the meaning of embedded which was addressed by Fern. Yes, it was embedded on two devices, but the demo didn’t show how it might be embedded in business applications. It stuck with the flashy concept of wearables.
OpenText might have something good with their analytics portability, but I don’t think the demo presents it to a business audience. Yes, techies will understand the underpinnings that make it cool, but the business folks writing checks need to see something that justifies the expenditure and I don’t think that’s shown.
Fern Halper did another good job of putting the adoption of analytics into perspective. This time, with a framework for better understanding embedded analytics.
Mark Gamble did a passable job of presenting OpenText’s solution but I feel he must do a better job of figuring out a business message.
TDWI’s data shows the early state of adoption that exists in the market. Fern Halper’s framework will help companies better understand how to move into the arena, but only if the companies providing those solutions can better present how they’ll help solve business issues.
I’ve probably used this in other columns, but that’s life. MapR’s presentation to the BBBT reminded me of Yogi Berra’s statement that it feels like déjà vu all over again. Wait, if I think I’ve done this before, am I stuck in a déjà vu loop?
The presentation was a tag team effort of Steve Wooledge, VP Product Marketing, and Tomer Shiran, VP Product Management.
The first part of the déjà vu was good. People love to talk about freeware, but mission critical solution won’t be trusted on such. Even before Linux, before Unix, software came out and it took companies to package it with service and support to provide constancy and trust for widespread IT adoption. MapR is a key company doing that with Apache Hadoop, the primary open source technology for big data applications.
They’ve done the job well, putting together a strong company that, quite reasonably, has attracted some great investors and customers. Of course, because Hadoop is still in its infancy, even a leading company such as MapR only mentions 700 customer, companies paying for licenses; but that’s a statement about big data’s still fairly limited impact in operational systems not a knock on MapR.
Their vision statement is simple: “Empowering the As-it-happens business by speeding up the data-to-action cycle.” Note the key: Hadoop is batch oriented and all the players realize that real-time analysis matters for some key sales and marketing applications. Companies are now focusing on how fast they can get information out of the databases, not what it takes to get data in. A smart move but only half the equation.
One key part of the move to package open source into something trusted was pointed out by Steve Wooledge. When the company polled customers about why they chose MapR, the largest response was availability, the up time of the system. Better performance wasn’t far behind, but it’s clear that the company understands that availability is a critical business issue and they seem to be addressing it well.
Where the déjà vu hits in a not-so-positive way is the regular refrain of technologists still not quite getting business – even when they try. This isn’t a technology problem but an innovator’s problem. When you get so wrapped up in the cool things you’re doing, you think that you need to lead with the cool things, not necessarily what the market wants.
One example was when they were describing the complexity of the MapR packaging. Almost all the focus was on the cool buzzwords of open source. Almost lost in the mix was the mention that their software supports NFS. It was developed more than 30 years ago and helps find files on networks. That MapR helps link both the latest and the still voluminous data in existing file systems is a key point, something that can help businesses understand that Hadoop can be integrated into existing systems and infrastructure. However, it’s not cool so the information is buried.
The final thing I’ll mention about the existing products is that MapR has built a nice three product suite, providing open source, mid-tier and full enterprise versions. That’s the perfect way to address the open source conundrum and move folks along the customer curve.
Sorry, couldn’t help the drill bit reference. Tomer Shiran took the later part of the presentation to show off Apache’s latest data toy, Apache Drill, intended to bridge the two worlds of data. The problem I saw was one not limited to Tomer, MapR or even Apache, but to all folks with with what they think of as new technology: Over hype and an addiction to revolutionary rather than evolutionary words and messages. There were far too many phrases that denigrated IT and existing technology and implied Drill would replace things that weren’t needed. When questioned, Tomer admitted that it’s a compliment; but the unthinking words of many folks in the industry set out a pattern inimical to rapid adoption into the Global 1000’s critical information paths.
Backing up that was a reply given to one questioner: ““CIO of one of the largest tech companies said they can’t keep doing things the same way.” Tech companies tend to be bleeding edge by nature, they do not represent the fuller business world. More importantly, the idea that a CIO saying she needs to change doesn’t mean the CIO is planning on throwing out existing tools that work. It means she wants to expand and extend in a way to leverage all technology to provide better decision making capabilities to the rest of the CxO suite.
Another area of his talk finally brought forward, through a very robust discussion, of one terminology issue that many are having. Big data folks like to talk about “no schema” but that’s not really true. Even when they modify the statement to be “schema on read” it’s missing the point.
They seem to be confusing fixed layout, relational records with the theory of schemas. XML is a schema for data exchange. It’s very flexible and can be self-defined, but it’s a schema. As it came from SGML, it’s not even the first iteration of flexible schemas. The example Mr. Tomer gave was just like an XML schema. Both data source and data recipient have to know some basic information such as field names in order to make sense of data, so there’s a schema.
Flexible schemas not only aren’t new, they don’t obviate the need for flexible schemas. They’re just another technique for managing the wide variety of data that business wishes to turn into information. As long as big data folks misusing a term and acting as if they have something revolutionary, the longer they’ll retard their needed incursion into IT and business information.
Hadoop and big data aren’t going anywhere except forward. The question is at what speed. There are some great things happening in both the Apache open source world and MapR’s licensed support for that world, but the lack of understanding of existing IT and business is retarding adoption of the new and exciting technologies.
When statements such as “But the sales guy won’t do X” are used by folks who have never been in and don’t understand sales, they’re missing the market. Today’s sales person is looking for faster and more accurate information, and is using many tools people would have said the same thing about only ten years earlier. In the meantime, sales management and the CxO suite who provide guidance for the sales force are even more interested in big picture information coming from massaging large data sources.
The folks in the new arenas such as Hadoop need to realize that they are complementary to existing technologies and that can help both IT and business. When pointing that out, I was asked by one of the presenters if that meant he should do two case studies, one with Hadoop, flexible schema and one with old line uses, I gave a clear no. It should be one with new and one that shows new and existing data sources combining to give management a more holistic picture than previously possible.
Evolution is good. MapR can help. They need to do the tough part of technology and more their view from what they think is cool to what the market thinks is needed.
Data virtualization. What is it? A few companies have picked up the term and run with it, including last week’s BBBT presenter Denodo. The presentation team was Suresh Chandrasekaran, Sr. VP, North America, Paul Moxon, Sr. Director, Product Management & Solution Architecture, and Pablo Alvarez, Sales Engineer. Still, what I’ve not seen is a clear definition of the phrase. The Denodo team did a good job describing their successes and some features that help that, but they do avoiding a clear definition.
The companies doing data virtualization are working to create a virtual data structure where the logical definitions link back to disparate live systems instead of overlaying a single aggregated database of information. It’s the concept of a federated data warehouse from the 1990s, extended past the warehouse and now more functional because of technology improvements.
Data virtualization (and note that, sadly, I don’t create an acronym because DV is also data visualization and who needs the confusion. So more typing…) is sometimes thought of as a way to avoid data warehouses by people who hear about it at a high level, but as the Denodo team repeatedly pointed out, that’s not the case. Virtualization can simplify and speed some types of analysis, but the need for aggregated data stores isn’t going away.
The biggest problem with virtualization for everything is operational systems not being able to handle the performance hits of lots of queries. A second is that operational systems don’t typically track historical information needed for business analysis. Another is that very static data in multiple systems that’s accessed frequently can create an unnecessary load on today’s busier and busier networks. Consolidating information can simplify and speed access. Another is that change management becomes a major issue, with changes to one small system potentially causing changes to many systems and reports. There are others, but they in no way undermine the value that is virtualization.
As Pablo Alvarez discussed, virtualization and a warehouse can work well together to help companies blend data of different latencies, with virtualization bringing in dynamic data to mesh with historic and dimensional information to provide the big picture.
Denodo seems to have a very good product for virtualization. However, as I keep pointing out when listening to the smaller companies, they haven’t yet meshed their high level ideas about virtualization and their products into a clear message. The supposed marketechture slide presented by Suresh Chandrasekaran was very technical, not strategic. Where he really made a point was in discussing what makes a Denodo pitch successful.
Mr. Chandrasekaran states that pure business intelligence (BI) sales are a weak pitch for data virtualization and that a broader data need is where the value is seen by IT. That makes absolute sense as the blend between BI and real-time is just starting and BI tends to look at longer latency data. It’s the firms that are accessing a lot of disparate systems for all types of productivity and business analysis past the focus on BI who want to get to those disparate systems as easily as possible. That’s Denodo’s sweet spot.
While their high level message isn’t yet clarified or meshed with markets and products, their product marketing seems to be right on track. They’ve created a very nicely scaled product
Denodo Express is free version of their platform. Paul Moxon stated that it’s fully functional, but it can’t be clustered, has a limitation of result set size and can’t access certain data sources. However, it’s a great way for prospects to look at the functionality of the product and to build a proof-of-concept. The other great idea is that Denodo gives Express users a fixed time pricing offer for enterprise licensing. While not providing numbers, Suresh stated that the offer was working well as an incentive for the freeware to not be shelfware, for prospects to test and move down the sales funnel. To be blunt, I think that’s a great model.
One area they know is a weakness is in services, both professional services and support. That’s always an issue with a rapidly growing company and it’s good to see Denodo acknowledge that and talk about how they’re working to mitigate issues. The team said there are plans to expand their capital base next year, and I’d expect a chunk of that investment to go towards this area.
The final thing I’ll note specifically about Denodo’s presentation is their customer slides. That section had success stories presented by the customers, their own views. That was a strong way to show customer buy in but a weak way to show clear value. Each slide was very different, many were overly complex and most didn’t clearly show the value they achieved. It’s nice, but customer stories need to be better formalized.
As pointed out above, in the description of virtualization, it’s a very valuable tool. The market question is simple: Is that enough? There have been plenty of tools that eventually became part of a larger market or a feature in a larger product offering. What about data virtualization?
As the Denodo team seems to admit, data virtualization isn’t a market that can stand on its own. It must integrate with other data access, storage and provisioning systems to provide a whole to companies looking to better understand and manage their businesses. When there’s a new point solution, a tool, partnerships always work well early in the market. Denodo is doing a good job with partners to provide a robust solution to companies; but at some point bigger players don’t want to partner but to provide a complete solution.
That means data virtualization companies are going to need to spread into other areas or be acquired. Suresh Chandrasekaran thinks that data virtualization is now at the tipping point of acceptance. In my book, given how fast the software industry, in general, and data infrastructure markets, in particular, grow and evolve, that leaves a few years of very focused growth before the serious acquisitions happen – though I wouldn’t be surprised if it starts sooner. That means companies need to be looking both at near term details and long term changes to the industry.
When I asked about long term strategy, I got the typical startup answer: They’re focused on internal growth rather than acquisition (either direction). That’s a good external message because folks who want a leading edge company want it clear that they’re using a leading edge company, but I hope the internal conversations at the CxO level aren’t avoiding acquisition. That’s not a failure, just a different version of success.
Denodo is a strong technical company focused on data virtualization in the short run. They have a very nicely scaled model from Denodo Express to their full product. They seem to understand their sweet spot within IT organizations. Given that, any large organization looking to get better access to disparate sources of data should talk with Denodo as part of their evaluation process.
My only questions are in marketing messages and whether or not Denodo be able to change from a technical sales to a higher level, clearer vision that will help them cross the chasm. If not, I don’t think their product is going anywhere, someone will acquire them. Regardless, Denodo seems to be a strong choice to look at to address data access and integration issues.
Data virtualization is an important niche, the questions remain as to how large is the niche and how long it will remain independent.
Revolution Analytics presented to the BBBT last Friday. The company is focused on R with a stated corporate vision of “R: The De-facto standard for enterprise predictive analytics .” Bill Jacobs, VP, Product Marketing, did most of the talking while Steve Belcher, Sales Engineer, gave a presentation.
For those of you unfamiliar with R as anything other than a letter smack between Q and S, R is an open source programming language for statistics and analytics. The Wikipedia article on R points out it’s a combination of Scheme and S. As someone who programmed in Scheme many years ago, the code fragments I saw didn’t look like it but I did smile at the evolution. At the same time, the first thing I said when I saw Revolution’s interactive development environment (IDE) was that it reminded me of EMACS, only slightly more advanced in thirty years. The same wiki page referenced earlier also said that R is a GNU project, so now I know why.
Bill Jacobs was yet another vendor presenter who has mentioned his company realized that the growth of the Internet of Things (IOT) means a data explosion that leaves what is currently misnamed as big data in the dust as far as data volumes. He says Revolution wants to ensure that companies are able to effectively analyze IOT and other information and that his company’s R is the way to do so.
Revolution Analytics is following in the footsteps of many companies which have commercialized freeware over the years, including Sun with Unix and Red Hat with Linux. Open source software has some advantages, but corporate IT and business users require services including support, maintenance, training and more. Companies which can address those needs can build a strong business and Revolution is trying to do so with R.
I mentioned the GUI earlier. It is very simple and still aimed at very technical users, people doing heavy programming and who understand detailed statistics. I asked why and was told that they felt that was their audience. However, Bill had earlier talked about analytics moving forward from the data priests to business analysts and end users. That’s a dichotomy. The expressed movement is a reason for their vision and mission, but their product doesn’t seem to support that mission.
Even worse was the response when I pointed out that I’d worked on the Apple Macintosh before and after MPW was released and had worked at Gupta when it was the first 4GL language on the Windows platform. I received as long winded answer as to why going to a better and easier to use GUI wasn’t in the plans. Then Mr. Jacobs mentioned something to the effect of “You mentioned companies earlier and they don’t exist anymore.” Well, let’s forget for a minute that Gupta began a market, others such as Powersoft did well too for years, and then Microsoft came out with its Visual products to control the market but that there were many good years for other firms and the products are still there. Let’s focus on wondering when Apple ceased to exist.
It’s one thing to talk about a bigger market message in the higher points of a business presentation. It’s another, very different, thing to ensure that your vision runs through the entire company and product offering.
Along with the Vision mentioned above, Revolution Analytics presents a corporate mission to “Drive enterprise adoption of R by providing enhanced R products tailored to meet enterprise challenges.” Enterprise adoption will be hindered until the products reflect an ability to work for more than specialist programmers but can address a wider enterprise audience.
Part of the problem seems to be shown in the graphic below.
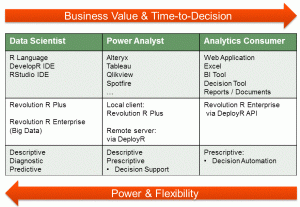
Revolution deserves credit for accurately representing the current BI space in snapshot. The problem is that it is a snapshot of today and there wasn’t an indication that the company understands how rapidly things change. Five to ten years ago, the middle column was the left column. Even today there’s a very technical need for the people who link the data to those products in order to begin analysis. In the same way, much of what is in the right column was in the middle. In only a few years, the left column will be in the middle and the middle will be on the right.
Software evolves rapidly, far more rapidly that physical manufacturing industries. Again, in order to address their enterprise mission, Revolution Analytics’ management is going to have to address what’s needed to move towards the right columns that mean an enterprise adoption.
One thing they’ve done very well is to build out the product suite to attract different sized businesses, individual departments and others with a scaled product suite to attract a wider audience.

Revolution Analytics product suite
They seem to have done a good job of providing a layered approach from free use of open source to enterprise weight support. Any interested person should talk with them about the full details.
R is a very useful analytical tool and Revolution Analytics is working hard to provide business with the ability to use R in ways that help leverage the technology. They’re working hard to support groups who want pure free open source and others who want true enterprise support in the way other open source companies have succeeded in previous decades.
Their tool does seem powerful, but it is still clearly and admittedly targeted at the very technical user, the data priests.
Revolution Analytics seems to have a start to a good corporate mission and I think they know where they want to end up. The problems is that they haven’t yet created a strategy that will get them to meet their vision and mission.
If you are interested in using R to perform complex analysis, you need to talk to Revolution Analytics. They are strong in the present. Just be aware that you will have to help nudge them into the future.
I’ve been in computing business for almost thirty five years, but until this year it was always working for vendors or systems integrators. As a newly minted analyst, I’ve stayed away from very negative reviews. I’ve watched a few bad webinars recently and made the choice not to blog about them. However, as I’ve seen more and more, I’ve realized that doesn’t help the industry and I can’t remain silent.
On Tuesday, I watched a webinar by David Loshin, President of Knowledge Integrity, and Ramesh Menon from Cray. It was not pretty.
Let’s take, for instance, David Loshin’s five points for big data:
The first item has been around since client/server application first came to the fore. Big data has grown, in part, because of its ability to scale large volumes of data. This is nothing new.
Memory? It was a great point years ago, with Tableau and others having pushed it for quite a while. However, the last year or two we’ve been hitting the limits of pure memory solutions and I’ve seen a number of presentations from vendors focused on better integrating memory and disk depending on data latency needs. David’s statement that ““We will start seeing more applications using memory rather than disk,” is wrong. We’ll see more applications better leveraging memory, but disk isn’t going anywhere.
The Hadoop organization’s release of Hadoop v2, YARN, is a clear indication of the limitations of 1.0 and why people have also been talking about it for years. However, in the presentation, leading with 2.0 would have been better than again being a laggard about the known issues with 1.0. Either people use Hadoop and already know the issues or haven’t yet used it and will start with 2.0.
It’s not real-time ingestion the critical issue and I would have liked to see him focus more on the second half of the fourth bullet. Real-time extractions of information are moving much more rapidly than the ability to integrate it with the rest of corporate information and to provide analytical to that information.
David’s final point is the only timely one. People have recently begun to remember that evolution is easier than revolution and I’ve seen a number of vendors begin to focus on providing access to the new data sources via SQL. A lot more people providing business insight to corporations know SQL and that needs to be made available. Ramesh Menon said it better, but the point is here.
The biggest problem I had was with Loshin’s forward looking statement. I’ll almost ignore that nonsense about data lake, he’s not the only one busy trying to use a new, supposedly fancier, term for the ODS, but I’ll mention it anyway. The issue was that he claimed he saw data management moving away from the data lake as we move to in-memory. Really? The ODS isn’t going anywhere. It’s nonsense to thing that every bit of corporate information needs to reside in memory, just in case it might be needed. The ODS is becoming the central source of all operational and business data. Individual business intelligence tools and needs will drive in-memory usage for near real-time needs of specific departmental, divisional or corporate level analytics needs, but there will always be a non-memory source for all that information in order to provide consistency, appropriate levels of control and to handle data governance issues.
Now we turn to Ramesh Menon. His presentation was better than David Loshin’s, but not by much. I’m sorry, there’s no excuse for someone who puts himself forward as a voice of the industry to not understand the difference between a premise and a premises. Considering he used premise correctly in his presentation, it was terrible that it was used three times before that while describing “on-premise” computing. Everyone in our industry needs to sit down, focus and practice saying the right word.
His customer use case was a very jumbled story and an overcrowded slide with the main point being “the customer had a lot of data.” I wouldn’t have guessed. He needs to talk more about solutions, how Cray address the data.
As mentioned above, Ramesh had a very clear point about the difference between data scientists and business analysts being one reason that Hadoop 2.0 is important. The move from batch to lower latency access is part of the difference between a data scientist, someone wanting to be the priest at the temple, and a business analyst, a much larger group working to provide wider access to business information. Updating Hadoop is critical to the ability to keep it relevant.
That was a key point, the problem is that Ramesh isn’t the analyst, he’s Cray’s spokesperson. The discussion shouldn’t have been about generalities but about how Cray must have focused on Hadoop 2.0 for the Urika-XA appliance – but that wasn’t made clear. It was in the data sheet images plopped into the presentation, but reasons and results should have been openly discussed.
I’ll end with the one very interesting point from Mr. Menon’s presentation. He had a slide where he discussed four phases in the analytics pipeline: ETL, algorithms, analysis and visualization. His point is that there are very different resource requirements for each phase of the pipeline. This could be an entire presentation itself and Ramesh could focus and expand this, explaining how Cray helps to address part or all of those requirements to help present Cray to the industry.
The analysis got a couple of things right, but was mostly too late or wrong. The corporate presentation didn’t clearly link Cray to the issues involved. Both presentation halves were far to generic and descriptive with almost no descriptive takeaways. Furthermore, you could tell that neither presenter seemed to have put much time and effort into the webinar by both the content and presentation styles.
People need to learn that “there’s no such thing as bad press” is only something said by entertainers. It’s not enough to have a webinar to get your name out there. Lots and lots of companies are doing that. Thought needs to go into the presentation and practice needs to go into delivery.
There were some good tidbits in the presentation, but overall it was a mess. I was very disappointed in the hour that I lost.
Last Friday’s BBBT presentation was by Michael Whitehead, CEO, WhereScape. The company seems to have a very interesting and useful product, but there’s a huge communications gap that needs to be addressed.
One marketing issue to start was that I got most of this section from my own experience and WhereScape’s web site, not from Michael’s presentation. When someone begins a presentation by proudly announcing it is ““guaranteed there’s no corporate marketing in the presentation at all” while you’re presenting to a group of analysts, there’s a disconnect and it shows.
WhereScape has two products, Red and 3D, to help build and maintain data structures. The message is focused on data warehouses, but I’ll discuss that more in the next section. One issue was that their demonstration didn’t work as there seemed to be a problem connecting between their tablet and the BBBT display system, so much of what I’m saying is theory rather than anything demonstrated.
Red is their tool to build data warehouses. Other tools exist and have been around for decades, Informatica being just one competing firm.
3D is where the differentiation comes in. Everyone in IT understands that nightmare that is upgrading major software installations such as ERP, CRM and EDW systems. Even migrating from one version to the next of a single vendor can involve months of planning, testing and building, followed by more months of parallel runs to be safe. A better way of analyzing and modifying data structures that can compress the time frame can have a large positive impact upon a corporation. That’s what WhereScape is attempting.
However, their message is all “Automation! Automation! Automation!” and the short part of the demo that worked showed some automated analysis but a lot of clicks necessary to accomplish the task. From what I saw, it will definitely speed up the tasks, if as advertised, with clear time and money savings, but it’s not as automated as implied and I think a better message is needed.
In addition, their message is focused on data warehouses while Michael said “We’re in the automation business not the data warehouse business,” which really doesn’t say anything.
Michael did talk for a bit about the bigger data picture that includes data warehouses as part of the full solution, but again there’s no clear message. While saying that he doesn’t like the term Data Lake, he’s another that can’t admit that it’s just the ODS. There’s also a discussion of the logical data warehouse, also not something new.
One critical and important thing Mr. Whitehead mentioned was something I’ve heard from a few people recently, the point that Hadoop and other “unstructured databases” aren’t really unstructured, they support late binding, the ability to not have to define a structure a priori but to get the data and then understand and define a useable structure for analysis.
This is the tough one and not something I’m going to solve in a short column. The company is targeting a sweet spot. Data access has exploded and that includes EDW’s not going away, the misnamed concept of Big Data and much more. Many products have been created to build databases to manage that data but the business intelligence industry is still in the place packaged, back-end systems were in the 1990s. Building is easier than maintaining and upgrading. A firm that can help IT manage those tasks in an efficient, affordable and accurate way will do well.
WhereScape seems to be aimed at that. However, their existing two-fold focus on automation and data warehousing is wrong. First, it doesn’t seem all that automated yet and, even if it was, automation is the tool rather than the benefit. They need to focus on the ROI that the automation presents IT. Second, from what was discussed the application has wider applicability than just EDW’s. It can address data management issues for a wider area of business intelligence sources and the message needs to include that.
Though the presentation was very disjointed, WhereScape seems to have focused on a clearly relevant and necessary niche in the market: How to better maintain and upgrade the major data sources needed to gain business understanding.
Right now, while there is a marketing staff at the company, WhereScape’s message seems to be solely coming from the co-founder and CEO. While that was ok in the very early days, they have some good customer stories, having led with Tesco’s success in this presentation, and it’s time to leverage a stronger and clearer core message to the market.
Where the issue seems to be is the problem I’ve repeatedly seen about messaging. The speed of the industry has increased and business intelligence is, on a whole, crossing Jeffrey Moore’s chasm. That means even younger firms need to transition from a startup, technically focused, message to a broader one much more rapidly than vendors needed to do so in the past.
While WhereScape has what seems to be the strong underpinnings of a successful product, they need to do some seriously brainstorming in order to clarify and incorporate a business oriented messaged throughout their communications channels – including in presentations by founders.
Data warehouse theory originally posited extracting data from systems, performing transformations on them and loading the resulting schemas into the data warehouse. It was a straight flow of information. However, the difference between theory and practice quickly reared its head. Today, people are talking about Data Lakes and Data Swamps. They’re not new, they’re just the ODS updated for modern data.
Academics don’t have to deal with operational systems. In the 1980s and 1990s, those systems were growing, with ERP, CRM and other systems increasing the complexity and volume of data. Those mission critical systems, however, weren’t designed for extraction of information. They were primarily running on RDBMS systems that had locking schemas that could grind process and transactional systems to a halt while and extraction program kept open large blocks of records while transforming basic data in star schemas. Something needed to be done.
There was also a secondary effect that was very important to some people. IT, just as with ever other department in a large enterprise, isn’t monolithic. The people managing the operational systems knew their systems were mission critical and also knew how, in reality, those systems were big but fragile. They weren’t happy with opening their operational systems to other IT folks who were interested in non-operational things. Those folks answering other business problems? They were viewed as intruders, getting in the way of the “real work.”
For both reasons, intrusions into the operational systems were something to be kept to a minimum. IT organizations began using an Operational Data Store (ODS) to quickly open the operational systems, suck all the data out, willy-nilly (yes, I decided to use that term in a tech article…), and then go back to prime performance in an isolated system. 
It was then the ODS that was the source of the data warehouse ETL process. On a tangent, this is why the people now arguing about ETL v ELT amuse me. It’s been ELETL for decade, if we want to be honest; but who cares? I’d rather have a BLT than spend so many cycles over slightly different acronyms for concepts that ETL handily describes, even in permutations.
The IT folks who were working to provide reports for mid- and high-level managers were always trying to tweak enterprise software reports, trying to extract nuggets of value. The data warehouse was a step forward and helped build a bigger picture. However, the creation of star schemas and other DW techniques aggregated data and lots a lot of detail. A manager would see an issue and want to backtrack, to drill-down into the data to know more.
The ODS became the way to do so. Very quickly, the focus changed from ODS in front of the data warehouse to both working side-by-side. Having all that raw data available gave the business analysts a way of providing much more detail and information to the business user. The first big BI companies, those such as Cognos, Business Objects and more, leveraged the two data stores to provide an ability to drill down past the aggregate information into the more detailed data.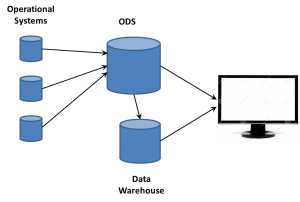
Having that large volume of data from multiple operational systems also intrigued people who weren’t data warehouse focused. They wanted to sift the raw data for technical or performance trends, things that weren’t of interest to the typical DW designers and users, but were important to mid-level management in manufacturing, marketing and other departments. Business analysts supporting those people began to turn to more and more analysis directly on the ODS data
That was happening in the 1990s, at the same time another key phenomenon was growing: The Web. The growth of the web meant a lot more data about a lot more things. Web sites are operational systems to marketing in just as critical a way as an assembly line is to manufacturing. People became interested in ensuring that what visitors to web sites did was captured and available for analysis. However, as the volume of web traffic grew exponentially, new issues had to be looked at to handle that data.
Columnar databases were one solution, a way to speed up analysis of dimensions of information across individual records. The vastly larger amount of data also helped push emerging MPP technologies and drove creation of Hadoop and other technologies that could manage much larger data sources much faster and more cost efficiently than could individual Unix servers.
However, the web folks were new to IT and grew up in a different generation than the folks who designed and drove data warehousing. It’s natural to  want to take ownership of concepts, especially those on the edge. So the folks working with these new data sources began talking about Big Data as somehow completely different than what came before. If that was the case, they needed to think of some term for the database where they dumped all the data extracted from web sites. Data Lakes became one term. We’ve heard data swamp and other attempts to create unique terms so a company can differentiate itself from others. However, there’s already a name.
want to take ownership of concepts, especially those on the edge. So the folks working with these new data sources began talking about Big Data as somehow completely different than what came before. If that was the case, they needed to think of some term for the database where they dumped all the data extracted from web sites. Data Lakes became one term. We’ve heard data swamp and other attempts to create unique terms so a company can differentiate itself from others. However, there’s already a name.
The ODS exists. It’s evolved. It’s moved forward. But it’s still the ODS.
“But,” you say, “an ODS is operational information and the data lake is so much more!” Well, not quite. There are two main problems with that argument.
First, times change. When the ODS was coined, the focus was on the back-end systems such as ERP, CRM, accounting and other fairly closed systems. It was before the web, before the ubiquity of mobile devices, before the wall between back-end and customer-facing systems was destroyed.
As mentioned, not just web sites are but even the internet is an operational system for your business – and not just for ecommerce companies. From lead generation, to maintenance and training, the internet is a key tool for providing operational support and generating business critical operational details.
Second, just as ETL can mean a number of things, so can ODS extend past a pure theory while still being relevant. CRM systems are considered operational but still contained sentiment and other information in comments fields. Just so, the vast volume of data from a call center’s voice recording system being dumped into the ODS have two components. There are basic details about the operation of the call center, things such as number of calls, call length and other details that are purely operational. There are also additional details about customers that can be distilled for strategy purposes, including the ability to provide sentiment analysis. Just because an operational system captures data that can be used for more than purely operational decision making doesn’t obviate that the information extracted resided in an ODS.
It’s a need of information technologists from all generations to realize that things change but retain context. The ODS isn’t what it was thirty years ago, but the data lake also isn’t some new creation born full blown from the web. There are few truly revolutionary technologies. You can be a brilliant person and contribute much to technology and business and still not be a revolutionary.
The ability to manage the vastly larger amounts of data than we had twenty years ago is critical. There are many innovative things being done. However, I consider the first expert systems, the first MPP algorithms and other similar technologies to be revolutionary. The fact that what is being done to allow business to gain insight combining more and more data from even more diverse sources is no less valuable to the industry because it is instead an evolutionary change.
The ODS has evolved. It doesn’t need a new name, just a tad more respect.
“No SQL!”
“Hadoop doesn’t require you to work in SQL!”
The claims are everywhere, but do they mean anything? To ruin the suspense: No.
There seems to be a big misunderstanding or a big lack of communications in the realm of big data. I keep hearing company after company compare Hadoop to SQL, claiming the former is somehow better than the later. Sadly, that’s comparing apples to screwdrivers.
Hadoop is a database technology. It’s based on MPP architecture for the Cloud. Hadoop compares to flat files, relational databases and other methods for storing information in structures.
SQL is an query language. It’s similar to an API in that it’s just a way to communicate with the data source. Long ago, in the dawn of time, SQL was tightly tied to DB2 and the relational environment that spawned the syntax. However, along came the 1980s, Unix servers and PCs, and the need to access lots of different data sources and an unwillingness to have to have very separate query languages for each data source.
Along came ODBC to the rescue. It standardized core query syntax using the SQL paradigm and allowed, under the covers, the ODBC developer to use an API to translate almost standard queries into the language of each data source. It extended SQL to access new things.
In the meantime, as RDBMS technologies began to try to find ways around the basic limitations of relational databases, the companies added extra features such as stored procedures that extended SQL even further from the origins of basic definition and query of relational structures.
So now we have a mass of coders who have only worked with large, primarily Web oriented databases using non-RDBMS technology. No surprise, they had to code their own interfaces and queries, getting into the details of the newer systems. At the same time, they probably brushed through and overview of RDBMS and SQL in school and then never used it again.
That meant a misunderstanding of the difference between database and query. Therefore, the message of No SQL will retard their progress in integrating their solutions with the existing IT data infrastructure.
There’s a large need for people who can work with Hadoop and other younger data sources. There’s also a vast pool of people who know SQL. Yes, there will always be a need for Hadoop gurus just as there is for every technology, but the folks wanting to get information out of data sources don’t need to know the data sources, they need to get the information – and they know SQL.
A number of vendors have figured that out and are now offering SQL as a means to access Hadoop. It’s a natural fit, an extension of what the people pushing Hadoop are hoping to achieve. Hadoop and other distributed, non-row based architectures are there to expand knowledge. They’re great ways to better understand the vast body of data coming in from many new sources. However, until you can get that data to the business knowledge worker, it’s not information. SQL is the clearest way to quickly bridge that gap.
The people who realize that it’s not an either/or decision, who understand that Hadoop and SQL not only can but should work together are the people who will drive their companies forward by quickly addressing real business needs.
SQL v Hadoop is the wrong conversation. SQL and Hadoop is the right one.
Today a webinar was hosted by Database Trend and Applications. While there are important things to talk about, I’ll start with the amusing point of the inverse relationship between company size and presenter title found in every webinar, but wonderfully on display here. The three presenters were:
The topic was “Accelerating your Analytics for Faster Insights.” That is a lot to cover in less than an hour, made more brief by a tag team of three people from different companies. I must say I was pleasantly surprised with how well they integrated their messages.
Mark Theissen was up first. There were a lot of fancy names for what Cirro does, but think ETL as it’s much easier. Mark’s point is that no single repository can handle all enterprise data even if that made sense. Cirro’s goal is to provide on-demand distributed analytics, using federation to link multiple data sources in order to help businesses analyze more complete information. It’s a strong point people have forgotten in the last few years during the typical “the latest craze will solve everything” focus on Hadoop and minimizing the role of getting to multiple sources.
Peter Hoopes then followed to talk about doing the analytics. One phrase he used should be discussed in more detail: “speed wins.” So many people are focused on the admittedly important area of immediate retail feedback on the web and with mobile devices. There, yes, speed can win. However, not always. Sometimes though helps too. That’s one reason why complex analysis for high level business strategy and planning is different that putting an ad on a phone as you walk by a store. There are clear reasons for speed, even in analytics, but it should not be the only focus in a BI decision.
IBM’s Amit Patel then came on to discuss the meat of the matter: DB2 Blu. This is IBM’s foray into in-memory, columnar databases. It’s a critical ad to the product line. There are advantages to in-memory that have created a need for all major players to have an offering, and IBM does the “me too!” well; but how does IBM differentiate itself?
As someone who understands the need for integration of transaction and analytic systems and agrees both need to co-exist, I was intrigued by what Amit had to say. Transactions going into normal DB2 environment while being shadowed into columnar BLU environment to speed analytics. Think about it: Transactions can still be managed with the row-oriented technologies best suited for them while the information is, in parallel, moved to the analytics database that happens to be in memory. It seems to be a good way to begin to blend the technologies and let each do what works best.
For a slightly techhie comment, I did like what Mr. Patel was saying about IBM’s management of memory and CPU. After all, while IBM is one of the largest software vendors in the world, too many folks forget their hardware background. One quick mention in a sentence about “hardware vendors such as Intel and IBM…” was a great touch to add a message that can help IBM differentiate its knowledge of MPP from that of pure software companies. As a marketing guy, I smiled big time at the smooth way that was brought up.
The three presenters did a good job in pointing out that the heterogeneous nature of enterprise data isn’t going away, rather it’s expanding. Each company, in its own way, put forward how it helps address that complexity. Still, it takes three companies.
As the BI market continues to mature, the companies who manage to combine the enterprise information supply chain components most smoothly will succeed. Right now, there’s a message being presented by three players. Other competitors also partner for ETL, data storage and analytics. It sounds interesting, but the market’s still young. Look for more robust messages from single vendors to evolve.