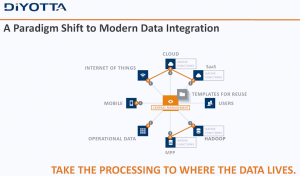
Data warehouse theory originally posited extracting data from systems, performing transformations on them and loading the resulting schemas into the data warehouse. It was a straight flow of information. However, the difference between theory and practice quickly reared its head. Today, people are talking about Data Lakes and Data Swamps. They’re not new, they’re just the ODS updated for modern data.
Data Warehouses and the ODS
Academics don’t have to deal with operational systems. In the 1980s and 1990s, those systems were growing, with ERP, CRM and other systems increasing the complexity and volume of data. Those mission critical systems, however, weren’t designed for extraction of information. They were primarily running on RDBMS systems that had locking schemas that could grind process and transactional systems to a halt while and extraction program kept open large blocks of records while transforming basic data in star schemas. Something needed to be done.
There was also a secondary effect that was very important to some people. IT, just as with ever other department in a large enterprise, isn’t monolithic. The people managing the operational systems knew their systems were mission critical and also knew how, in reality, those systems were big but fragile. They weren’t happy with opening their operational systems to other IT folks who were interested in non-operational things. Those folks answering other business problems? They were viewed as intruders, getting in the way of the “real work.”
For both reasons, intrusions into the operational systems were something to be kept to a minimum. IT organizations began using an Operational Data Store (ODS) to quickly open the operational systems, suck all the data out, willy-nilly (yes, I decided to use that term in a tech article…), and then go back to prime performance in an isolated system. 
It was then the ODS that was the source of the data warehouse ETL process. On a tangent, this is why the people now arguing about ETL v ELT amuse me. It’s been ELETL for decade, if we want to be honest; but who cares? I’d rather have a BLT than spend so many cycles over slightly different acronyms for concepts that ETL handily describes, even in permutations.
The ODS comes into its own
The IT folks who were working to provide reports for mid- and high-level managers were always trying to tweak enterprise software reports, trying to extract nuggets of value. The data warehouse was a step forward and helped build a bigger picture. However, the creation of star schemas and other DW techniques aggregated data and lots a lot of detail. A manager would see an issue and want to backtrack, to drill-down into the data to know more.
The ODS became the way to do so. Very quickly, the focus changed from ODS in front of the data warehouse to both working side-by-side. Having all that raw data available gave the business analysts a way of providing much more detail and information to the business user. The first big BI companies, those such as Cognos, Business Objects and more, leveraged the two data stores to provide an ability to drill down past the aggregate information into the more detailed data.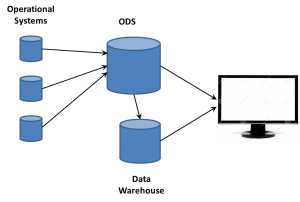
Having that large volume of data from multiple operational systems also intrigued people who weren’t data warehouse focused. They wanted to sift the raw data for technical or performance trends, things that weren’t of interest to the typical DW designers and users, but were important to mid-level management in manufacturing, marketing and other departments. Business analysts supporting those people began to turn to more and more analysis directly on the ODS data
The ODS comes to the fore – by another name
That was happening in the 1990s, at the same time another key phenomenon was growing: The Web. The growth of the web meant a lot more data about a lot more things. Web sites are operational systems to marketing in just as critical a way as an assembly line is to manufacturing. People became interested in ensuring that what visitors to web sites did was captured and available for analysis. However, as the volume of web traffic grew exponentially, new issues had to be looked at to handle that data.
Columnar databases were one solution, a way to speed up analysis of dimensions of information across individual records. The vastly larger amount of data also helped push emerging MPP technologies and drove creation of Hadoop and other technologies that could manage much larger data sources much faster and more cost efficiently than could individual Unix servers.
However, the web folks were new to IT and grew up in a different generation than the folks who designed and drove data warehousing. It’s natural to 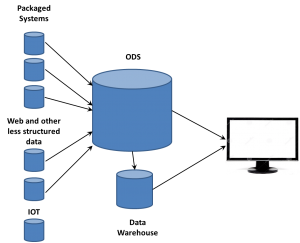 want to take ownership of concepts, especially those on the edge. So the folks working with these new data sources began talking about Big Data as somehow completely different than what came before. If that was the case, they needed to think of some term for the database where they dumped all the data extracted from web sites. Data Lakes became one term. We’ve heard data swamp and other attempts to create unique terms so a company can differentiate itself from others. However, there’s already a name.
want to take ownership of concepts, especially those on the edge. So the folks working with these new data sources began talking about Big Data as somehow completely different than what came before. If that was the case, they needed to think of some term for the database where they dumped all the data extracted from web sites. Data Lakes became one term. We’ve heard data swamp and other attempts to create unique terms so a company can differentiate itself from others. However, there’s already a name.
The ODS exists. It’s evolved. It’s moved forward. But it’s still the ODS.
Yes, really
“But,” you say, “an ODS is operational information and the data lake is so much more!” Well, not quite. There are two main problems with that argument.
First, times change. When the ODS was coined, the focus was on the back-end systems such as ERP, CRM, accounting and other fairly closed systems. It was before the web, before the ubiquity of mobile devices, before the wall between back-end and customer-facing systems was destroyed.
As mentioned, not just web sites are but even the internet is an operational system for your business – and not just for ecommerce companies. From lead generation, to maintenance and training, the internet is a key tool for providing operational support and generating business critical operational details.
Second, just as ETL can mean a number of things, so can ODS extend past a pure theory while still being relevant. CRM systems are considered operational but still contained sentiment and other information in comments fields. Just so, the vast volume of data from a call center’s voice recording system being dumped into the ODS have two components. There are basic details about the operation of the call center, things such as number of calls, call length and other details that are purely operational. There are also additional details about customers that can be distilled for strategy purposes, including the ability to provide sentiment analysis. Just because an operational system captures data that can be used for more than purely operational decision making doesn’t obviate that the information extracted resided in an ODS.
Summary
It’s a need of information technologists from all generations to realize that things change but retain context. The ODS isn’t what it was thirty years ago, but the data lake also isn’t some new creation born full blown from the web. There are few truly revolutionary technologies. You can be a brilliant person and contribute much to technology and business and still not be a revolutionary.
The ability to manage the vastly larger amounts of data than we had twenty years ago is critical. There are many innovative things being done. However, I consider the first expert systems, the first MPP algorithms and other similar technologies to be revolutionary. The fact that what is being done to allow business to gain insight combining more and more data from even more diverse sources is no less valuable to the industry because it is instead an evolutionary change.
The ODS has evolved. It doesn’t need a new name, just a tad more respect.