Here’s an article on Forbes about Tableau buying Empirical Systems.
Short post on Tableau acquiring an MIT AI spinoff
Leave a reply
Here’s an article on Forbes about Tableau buying Empirical Systems.
Cloudera held a pretty impressive web event this morning. It was a mini-conference, with keynotes, some breakout tracks and even a small vendor area. The event was called Cloudera Now, and the link is the registration one. I’ll update it if they change once it’s VOD.
The primary purpose was to present Cloudera as the company for data support in the rapidly growing field of Machine Learning (ML). Given the state of the industry, I’ll say it was a success.
As someone who has an MS focused on artificial intelligence (ancient times…) and has kept up with it, there were holes, but the presentations I watched did set the picture for people who are now hearing about it as a growing topic.
The cleanest overview was a keynote presentation by Tom Davenport, Professor of IT and Management, Babson College. That’s worth registering for those who want to get a well presented overview.
Right after that, he and Amy O’Conner, Big Data Evangelist at Cloudera, had a small session that was interesting. On the amusing side, I like how people are finally beginning to admit that, as Amy mentioned, that the data scientist might not be defined as just one person. I’ll make a fun “I told you so” comment by pointing to an article I published more than three years ago: The Myth of the Data Scientist.
After the keynotes, there were three session of presentations, each with three seminars from which to choose. The three I attended were just ok, as they all dove too quickly into the product pitches. Given the higher level context of the whole event, I would have liked them all to spent more time discussing the market and concepts far longer, and then had much briefer pitch towards the end of the presentations. In addition, they seem too addicted to the word “legacy,” without some of them really knowing what that meant or even, in one case, getting it right.
However, those were minor problems given what Cloudera attempted. For those business people interested in hearing about the growing intersection between data, analytics, and machine learning, go to Cloudera’s site and take some time to check out Cloudera Now.
I’ve seen a few company webinars recently. As I have serious problems with their marketing, but don’t wish that to imply a problem with technology, this post will discuss the issues while leaving the companies anonymous.
What matters is letting business decision makers separate the hype from what they really need to look at when investigating products. I’m in marketing and would never deny its importance, but there’s a fine line between good marketing and misrepresentation, and that line is both subjective and fuzzy.
As the title suggests, I’ll discuss the line by describing my views of two buzzwords in business intelligence (BI). The first has been used for years, and I’ve talked about it before, it’s the concept of self-service BI. The second is the fairly new and rapidly increasing use of the word “machine” in marketing
As I discussed in more detail in a TechTarget article, BI vendors regularly claim self-service when software isn’t. While advances in technology and user interface design are rapidly approaching full self-service for business analysts, the term is usually directed at business users. That’s just not true.
I’ve seen a couple of recent presentations that have that message strewn throughout the webinars, but the demonstrations show anything but that capability. The linking of data still requires more expertise that the typical business user needs. Even worse, some vendors limit things further. The analysts still create basic reports and templates, within which business people can wander with a bit of freedom. Though self-service is claimed, I don’t consider that to approach self-service.
The result is that some companies provide a limited self-service within the specified data set, a self-service that strongly limits discovery.
As mentioned, that self-service is either misunderstood or over promised doesn’t obviate that the technology still allows customers to gain far more insight than they could even five years ago. The key is to take the promises with a grain of salt.
When you see it, ignore the phrase “self-service.”
Prospective BI buyers need to focus on whether or not the current state of the art presents enough advantages over existing corporate methodologies to provide proper ROI. That means you should evaluate vendors based on specific improvements on your existing analytics and the products should be rigorously tested against your own needs and your team’s expertise.
Machine learning, to be discussed shortly, has exploded in usage throughout the software industry. What I recently saw, from one BI vendor, was a fun little marketing ploy to leverage that without lying. That combination is the heart of marketing and, IMO, differs from the nonsense about self-service.
Throughout the webinar, the presenter referred to the platform as “the machine.” Well, true. Babbage’s machines were analytic engines, the precursors to our computers, so complex software can reasonable be viewed as a machine. The usage brings to mind the concept of machine learning while clearly claiming it’s not.
That’s the difference, self-service states something the products aren’t while machine might vaguely bring to mind machine learning but does not directly imply that. I am both amused and impressed by that usage. Bravo!
This phrase needs a larger article, one I’m working on, but I would be remiss to not mention it here. The two previous sections do imply how machine learning could solve the self-service problem.
First, what’s machine learning? No, it’s not complex analytics. Expert systems (ES) are a segment of artificial intelligence focused on machines which can learn new things. Current analytics can use very complex algorithms, but they just drive user insight rather than provide their own.
Machine learning is the ability for the program to learn new things and to even add code that changes algorithms and data as it learns. A question to an expert system has one answer the first time, and a different answer as it learns from the mistakes in the first response.
Natural Language Processing (NLP) is more obvious. It’s the evolving understanding of how we speak, type and communicate using language. The advances have meant an improved ability for software to responds to people without clicking on lots of parameters to set search. The goal is to allow people to type or speak queries and for the ES to then respond with information at the business level.
The hope I have is that the blend will allow IT to set up systems that can learn the data structures in a company and basic queries that might be asked. That will then allow business users to ask questions in a non-technical manner and receive information in return.
Today, business analysts have to directly set up dashboards, templates and other tools that are directly used by business, often requiring too much technical knowledge. When a business person has a new idea, it has to go back to a slow cycle where the analyst has to hook in more data, at new templates and more.
When the business analyst can focus on teaching the ES where data is, what data is and the basics of business analysis, the ES can focus on providing a more adaptable and non-technical interface to the business community.
Machine learning, i.e. expert systems, and NLP are what will lead to truly self-service business applications. They’re not here yet, but they are on the horizon.
My latest article on Tech Target is about how Business Intelligence and the Internet of Things (IoT) overlap.
I have an article in the Spring TDWI Journal. It has now been six months and the organization has been kind enough to provide me with a copy of my article to use on my site: TDWI_BIJV21N1_Teich.
If you like my article, and I know you will, check out the full journal.
My latest Tech Target column is on storytelling.
A presentation last week, hosted by Database Trends and Applications (DBTA), was a great example of some interesting technical information presented poorly. As that sentence implies, this column is one about the marketing of business intelligence (BI), not about the technology – well, not much…
There were three presenters: Brian Bulkowski, CTO and Co-founder, Aerospike; Kevin Petrie, Senior Director and Technology Evangelist, Attunity; Reiner Kappenberger, Global Product Management, HPE Security – Data Security.
Brian was first at the podium. Aerospike is a company providing what they claim is a very high speed, scalable database, proudly advertising “NoSQL!” The problem they have is that they are one of many companies still confused about the difference between databases and SQL. A database is not the access method. What they’re really focused on in loosely structured data, the same way Hadoop and other newer databases are aimed. That doesn’t obviate the need to communicate via SQL.
He also said that the operational in-memory market is “owned by NoSQL.” However, there were no numbers. Standard RDBMS’s, columnar and NoSQL databases all are providing in-memory storage and processing. In fact, Information Management has a slide show of Gartner’s database analytics vendor report and you can see the breadth there. In addition, what I constantly hear (not statistically significant either…) is that Hadoop and other loosely-structured databases are still primarily for batch. However, as the slide show I just mentioned is in alphabetical order, and Aerospike is the first one you’ll see. Note again that I’m pointing out flaws in the marketing message, not the products. They could have a great in-memory solution, but that’s doesn’t mean NoSQL is the only NoSQL option.
The final key marketing issue is that he kept misusing “transactional.” He continued to talk about RDMS’s as transactional systems even while he talked about the power of Aerospike for better handling the transactions. In the later portion of his presentation, he was trying to say that RDBMS’s still had a place, but he was using the wrong term.
Attunity’s Kevin Petrie was second and his focus was on Attunity Replicate. The team of Aerospike and Attunity again shows the market isn’t yet mature enough to have ETL and databases come smoothly together. Kevin talked about their 35 sources and it seem that they are the front end in the marketing paring of the two companies. If you really need heterogeneous data sources and large database manipulation, you’ll need to look at the pair of companies.
My key issue with this section was one of enterprise priorities. Perhaps the one big, anonymous reference they both discussed drove the webinar, but it shouldn’t have owned the message. Mr. Petrie spent almost all his time talking about Hadoop, MongoDB and Kafka. Those are still bleeding edge tools while enterprise adoption requires a focus on integrating with standard and existing sources. Only at the end, his third anonymous case, did Kevin have a slide that mentioned RDBMS sources. If he wants to keep talking with people running experimental and leading edge tests of systems, that priority makes sense. If he wishes to talk to the larger enterprise market, he needs to turn things around.
The other issue was a slide that equated RDBMS, Data Warehouse and Hadoop as being on equal footing. There he shows a lack of business knowledge. The EDW, as an old TV would declare, is the one of these things that is not like the other. It has a very different purpose from the two database technologies and isn’t technology dependent.
Reiner Kappenberger gave a great presentation but it didn’t belong. It seems the smaller two firms were happy to get HP to help with the financing but they didn’t think about staying on message.
Let me make it very clear: Security is of critical importance. What Mr. Kappenberger had to say was very important for people to hear. However, it didn’t belong in this webinar. The topic didn’t fit and working to stuff three presenters into forty minutes is always tough. Another presentation where all three talked about how they work to ensure that the large volumes of data can be secure at multiple levels would have been great to hear – and I hope the three choose to create such a webinar.
This was two different webinars stuffed into one, blurring the message. In addition, Aerospike and Affinity either need to make sure they they’re not yet trying to address the mass market or they need to learn how to stop speaking to each other and other leading edge people and begin to better address the wider enterprise market.
The unnamed reference seemed to be a company that needed help with credit card transactions and fraud detection, and all three companies worked to provide a full solution. However, from a marketing standpoint I don’t think they did proper service to their project by this webinar.
I just saw an amusing presentation by SAS. Amusing because you rarely get two presenters who are both as good at presenting and as knowledgeable about their products. We heard from Mike Frost, Senior Product Manager for Data Management, and Wayne Thompson, Chief Data Scientist. They enjoy what they do and it was contagious.
It was also interesting from the perspective of time. Too many younger folks think if a firm has been around for more than five years, it’s a dinosaur. That’s usually a mistake, but the view lives on. SAS was founded almost 40 years ago, in 1976, and has always focused on analytics. They have been historically aimed at a market that is made up of serious mathematicians doing heavy statistical work. They’re very good at what they do.
The business analysis sector has been focused on less technical, higher level business number crunching and data visualization. In the last decade, computing power has meant firms can dig deeper and can start to provide analysis SAS has been doing for decades. The question is whether or not SAS can rise to the challenge. It’s still early, but the answer seems to be a qualified but strong “yes!”
Both for good and bad, SAS is the largest privately held software company, still driven by founder James Goodnight. That means a good thing in that technically focused folks plow 23% of their revenue into R&D. However, it also leaves a question mark. I’ve worked for other firms long run by founders, one a 25+ year old firm still run by brothers. The best way to refer to the risk is that of a famous public failure: Xerox and the PC. For those who might not understand what I’m saying, read “Fumbling the Future” by Smith and Alexander. The risk comes down to the people in charge knowing the company needs to change but being emotionally wedded to what’s worked for so long.
The presentation to the BBBT shows that, while it’s still early in the change, SAS seems to be mostly avoiding that risk. They’re moving towards a clean, easier to use UI and taking their first steps towards collaboration. More work needs to be done on both fronts, but Mike and Wayne were very open and honest about their understanding the need and SAS continuing to move forward.
One of the key points by Mike Frost is one I’ve also discussed. While they disagree with me and think the data scientist does exist, the SAS message is clear that he doesn’t work in a void. The statistician, the business analyst and business management must all work in concert to match technical solutions to real business information needs.
The focus of the presentation was on SAS LASR, their in-memory analytics server. While it leverages Hadoop, it doesn’t use MapReduce because that involves disk access during processing, losing the speed advantage of in-memory applications.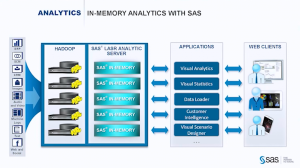
As Mike Frost pointed out, “It doesn’t do any good to run the right model too late.”
One point that still shows the need to think more about business, is that TCO was mentioned in passing. No slide or strong message supported the message. They’re still a bit too focused on technology, not what sells the business decision makers on business intelligence (BI).
Another issue was the large number of ancillary products in the suite, including Visual Data Explorer, Data Loader and others. The team mentioned that SAS is slowly moving through the products to give them the same interface, but I also hope they’re looking at integrating as much as possible so the users don’t have the annoyance of constantly moving between products.
One nice part of the demo was an example of discussing what SAS has termed “poorly structured data” as opposed to “unstructured data” that’s the rage in Hadoop. I prefer “loosely structured data.” Mike and Wayne showed the ability to parse the incoming file and have machine intelligence make an initial pass at suggesting fields. While this isn’t new, I worked at a company in 2000 that was doing that, it’s a key part of quickly integrating such data into the business environment. The company I reference had another founder who became involved in other things and it died. While I’m surprised it took firms so long to latch onto and use the technology, it doesn’t surprise me that SAS is one of the first to openly push this.
Another advantage brought by an older, global firm, related to the parsing is that it works in multiple languages, including right-to-left languages such as Hebrew and Arabic. Most startups focus on their own national language and it can be a while before the applications are truly global. SAS already knows the importance and supports the need.
The only big marketing mistake I heard was towards the end. While Frost and Thompson are rightfully proud of their products, Wayne Thompson crowed that “We’re not XXX,” a reference to a major BI player, “We’re end-to-end.” However, they’d showed only minimal visualization choices and their collaboration, admittedly isn’t there.
Even worse for the message, only a few minutes later, based on a question, one of the presenters shows how you export predicted values so that visualization tools with more power can help display the information to business management.
I have yet to see a real end-to-end tool and there’s no reason for SAS to push this iteration as more than it is. It’s great, but it’s not yet a complete solution.
SAS is making a strong push into the front end of analytics and business intelligence. They are busy wrapping tools around their statistical engines that will allow them to move much more strongly out of academics and the very technical depths of life sciences, manufacturing, defense and other industries to challenge in the realm of BI.
They’re headed in the right direction, but the risk mentioned at the start remains. Will they keep focused on this growing market and the changes it requires, or will that large R&D expenditure focus on the existing strengths and make the BI transition too slow? I’m seeing all the right signs, they just need to stay on track.
My latest article can be found here: http://searchbusinessanalytics.techtarget.com/feature/Business-intelligence-in-the-cloud-gives-boost-to-BI-process.
TechTarget took previously published article about self-service BI, bundled it with some other articles and reprinted it.