My latest Tech Target article is up at http://searchdatamanagement.techtarget.com/tip/SQL-vs-NoSQL-database-design-debate-isnt-even-a-real-fight.
SQL v NoSQL: It’s not really a fight
Leave a reply
My latest Tech Target article is up at http://searchdatamanagement.techtarget.com/tip/SQL-vs-NoSQL-database-design-debate-isnt-even-a-real-fight.
Yesterday’s TDWI webinar was focused on data-centric security. The tag team was Fern Halper, Research Director for Advanced Analytics, TDWI, and Jay Irwin, Director of InfoSec, Teradata. It’s always nice when the two halves of a sponsored presentation fit well. For that reason and for the content, this was a nice presentation.
Everyone in the industry knows that data breeches happen, and we all talk about the issue. I’ve seen a few articles and lists about the number of successful attacks, but Fern Halper pointed us to a nice graphic from Information is Beautiful. She also pointed to another study that showed that “In 2013, 33% of respondents said their company had a data breach. In 2014 the percentage has increased to 43%.” It’s always a race between black hats and white hats, so it’s important to minimize not only your chance of getting hacked, but also to minimize the importance and usefulness of data gained from successful hacks.
Ms. Halper than discussed four types of data security:
Each part is necessary but insufficient. Authorization is only as strong as people’s passwords. If it’s easy to steal the encryption key, encryption doesn’t matter. A robust security system leverages all the types.
One important note: Later in her presentation and throughout Jay Irwin’s section, encryption didn’t exist alone but alongside tokenization. The later is a different security technology, where characters, words, numbers and fields are replaced with other symbols, or tokens, that still look as if they’re real and can still be used in analysis. Mr. Irwin pointed out he prefers “data protection” as a rubric that covers all the techniques of data level security.
Along with that clarification, Jay Irwin also described the multiple layers as “Defense in Depth,” a concentric ring of security to ensure there’s no single point of failure. Jay also provided my favorite slide of the presentation. While it’s too wordy, it’s a pretty clear view of Teradata’s top-down approach.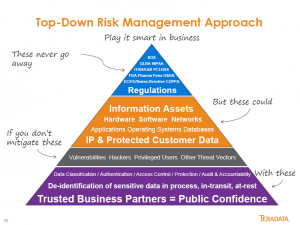
An organization must start with understanding the rules and regulations that drive data security. Only then can you identify the data assets that need special attention in order to protect them from hackers.
Jay has a lot more to say in a lot more detail, and I won’t cover it all. While I blog about webinars so you don’t have to watch, this one’s an exception. If you want to get a good, broad view of core data security issues, take some time and listen to the webinar.
The launch of Yellowfin DashXML included a round of global webinars mid-week. Well, not “included,” it’s more that the webinar was the entire launch. The new product feature is useful, but as I’m a marketing person I do have to question how they’ve handles the launch.
Yellowfin, as with many business intelligence (BI) vendors, is focused on visualization, providing business knowledge workers the ability to easily see information. The presentation was by John Ryan, Director of Product Marketing, and Teresa Pringle, Product Specialist. As is obvious from the title of the webinar, it was to announce the availability of the first version of DashXML, a utility within Yellowfin that allows easy integration of custom XML into dashboards and reports.
While they do sell directly to IT organizations who provide their interface to their corporate users, they also have a strong OEM business. As Mr. Ryan pointed out, “Embedding BI is a large chunk of Yellowfin’s business.” While direct label clients also want to customize user interfaces, DashXML seems much more valuable to the OEM customer base, providing an easier way to integrate standards from existing applications in order to have a more consistent interface.
The key word in that last sentence was “easier,” not “easy,” and that’s just fine for what is needed. This is XML. As Ms. Pringle explained, programmers will need to be very familiar with CSS manipulation and also with Java Script. DashXML is there to assist developers in providing customized visualizations, it is not for end users. The feature is available with a server license, providing deployment capability, and with a developer license for investigating the feature. It is not available as part of the per-user, distribution license for end users.
DashXML adds power and flexibility to Yellowfin’s offering and will better help its clients customize visualizations.
As much as the presenters seemed to be working to imply DashXML is a new product, it’s really a feature of their platform. While the title of the webinar was a launch, nothing in the presentation or on their site implies it’s really a launch.
Almost the entire presentation was about the existing Yellowfin offering. Teresa Pringle’s “demo” portion of the webinar started with a whole lot of customized interfaces and only spent a few minutes showing the DashXML features in design and only for a single report in a dashboard. You could get the idea that it would make things easier, but it was also clear that’s all it did. There’s nothing really new, nothing that Yellowfin clients aren’t doing now, it’s a way to save time and money. Mind you, those are very valuable things, but the presentation didn’t focus on any ROI those savings might present.
What’s more intriguing is that they held a webinar, yet their site doesn’t reflect that knowledge. As of the writing of this blog entry (24 hours after the webinar), a few things seem to be missing:
If the feature isn’t important enough to discuss on the web site, why have a webinar? After all, the purpose of a webinar is to drive interest in the product and one of the key follow ups for webinars should also be gaining information on your site to hopefully drive customer tracking and contact information as lead qualification.
DashXML is a nice addition that can help IT and OEM developers blend point-and-click development and coding to provide a customized visualization interfaces with better ROI. However, a week webinar and no content is neither a silent launch nor a strong one. Sadly, the marketing doesn’t rise to the quality of the product enhancement.
TDWI held a webinar to announce their latest major report. While there are always a lot of intriguing numbers in the reports, it’s also important to remember the TDWI audience is self-selecting. People interested in the latest information lean towards the leading edge so their numbers should be taken as higher than would be in the general IT market place. Still, the numbers as they change over time are valuable and the views of the analysts are often worth hearing.
As the webinar was pushing a major report, the full tag team was in attendance: David Stodder, TDWI Director for BI, Fern Halper, TDWI Director for Analytics, and Philip Russom, TDWI Director for Data Management.
David Stodder presented his section first, and one important point he made had nothing to do with numbers. He briefly discussed one quote and user story and it was from a government employee. Companies using Hadoop to better understand internet business and relationships tend to get almost all the press, but David pointed out the importance of data and analytics in helping governments better address the needs of their citizens.
A very intriguing set of numbers David provided was on how many responders were on current versions of software versus older versions. While you can see that some areas are more quickly adopting the SaaS model, that’s not the key the he pointed out. Only 27% of respondents said they’re on the current version of their data security software. A later slide shows that security is one reason for hesitation in the move to mobile, but Mr. Stodder rightly points out that underlying all the information channels is the basis of data security. It’s not a question of if you’ll get hacked but when, so data security should be kept updated.
The presentation was then turned over to Fern Halper. I look a bit askance at the claim that the Internet of Things (IoT) is a “trend.” Her data shows only 18% taking advantage of it today and 40% might be using in within three years. We’ve been talking about IoT for a while, and it’s clearly being slowly integrated into business, I wouldn’t say it’s as fashionable as the word trend would imply.
On the more useful side is the table she showed that’s simply titles “Analytics hits mainstream.” It not only shows that massive adoption of the last decade’s focus on dashboards and BI tools, but around 30% of respondents are using many of the newer tools and techniques and the next three years indicate a doubling in usage.
Philip Russom gave the final segment of the presentation. His first slide on the adoption of newer technologies for data warehousing showed something that many have finally admitted in the last year or no: No-SQL is an excuse made by people who don’t understand how business technology works. While the numbers show 28% of respondents using Hadoop, it also shows 22% using SQL on Hadoop. The number over the next three years are even more interesting: 36% say they’ll be using Hadoop and 38% will be using SQL on Hadoop. That means existing No-SQL folks will be moving to SQL.
The presentation ended with the team of analysts presenting their list of ten priorities for those people interested in emerging technologies. To me, the first isn’t the first among equals, it is set far above all the rest: Adopt them for their business benefits. All the other nine items are how IT addresses the challenges of new technologies, but those things are useless unless you understand how technologies will support business. Without that, you can’t provide an ROI and you can’t get business stakeholders to support you for long. That’s strategy, all the other points are just tactics.
As usual, get the report and browse it.
This is more of a marketing flavored post as the recent presentation seemed to miss its own point. The title implied it was about fast decision making, but Fern Halper, TDWI Research Director for Advanced Analytics, gave a rather generic presentation about the importance of operationalizing analytics.
Fern gave a nice presentation about operationalizing analytics, but it was not significantly different than her last few. In addition, some of the survey issues discussed were clearly not well thought out. For instance, Ms. Halper listed the expected growth of predictive analytics and web/mobile analytics as if they belonged in the same discussion. The fact that web and mobile are methods of display doesn’t overlap with whether they are used to display descriptive or prescriptive analytics. The growth of those display methods also don’t move away from the use of dashboards in CRM and ERP applications, as was implied, since those applications will migrate views to the new display methods.
The best thing mentioned by both Fern Halper and the SAP presenters was the fact that there were multiple references to that need for multiple data sources. Seeing the continued refocusing of many firms on wide data rather than big data is a good thing for the industry. Big data is more of a technical issue while wide data more directly addresses complex business environments.
Now I’m hoping for more people to begin to refer to loosely structured data rather than unstructured data. Linguists, I’m sure, are constantly amused at hearing languages referred to as unstructured.
The case study was by Raj Rathee, Director, Product Management, SAP. It was an interesting project at Lufthansa, where real-time analytics were used to track flight paths and suggest alternative routes based on weather and other issues. The business key is that costs were displayed for alternate routes, helping the decision makers integrate cost and other issues as situations occur. However, that was really the only discussion of fast decision making with analytics.
The final marketing note is that the Q&A was canned but the answers didn’t always sync up. For instance, the moderator asked one question of Fern, she had a good answer, but there was no slide in the pack about her response, just the canned SAP slide referenced by Ashish Sahu, Director, Product Marketing, SAP, after Ms. Halper spoke.
I think the problem was that the presenters didn’t focus down on a tight enough message and tried to dump too much information into the presentation. The message got lost.
A recent DBTA webinar was on how the data warehouse is still with us. It was by Sarah Maston, Developer Advocate, IBM Cloud Services. Simply put, it was a pitch for IBM and how their data warehousing solutions can help people more easily move to the cloud. Sarah was very knowledgeable, but she’s one of the smart folks I do suggest gets a class in presentation skills. IBM must have them and it would help her be even more powerful in her talks.
The core of the presentation was talking about how dashDB, IBM’s columnar, MPP database is perfect for data warehousing and how you can easily move information to it. Being at IBM, she had no hesitation talking about the big, visible name in Cloud: Amazon. Her claim is that IBM Cloudant is a much more powerful and agile tool for loading dashDB than is Amazon DynamoDB for Amazon Redshift. From my decades of high tech, I can believe it. IBM’s challenge is going to be whether or not they can communicate to the SMB market in ways they want to hear. That’s been a regular challenge for IBM.
One of the most interesting things Ms. Maston discussed was how to get information from systems into the data warehouse. A she said, in reference to IBM Bluemix, “meet the ODS.” I’ve previously said similar things and think it’s important to not forget the importance of the operational data store.
Data warehousing is not going away, it’s evolving. So too is the ODS. IBM is a company that often looks ahead very clearly but then sometimes misses the messaging. From the presentation, I see all the pieces are there, it’s early and they’ll grow, but it remains to be seen if they’ll learn how to address the market properly to get a major chunk of the business at which they’re aiming.
I’m still catching up and reviewed a video of last month’s Diyotta presentation to the BBBT. The company is another young, founded in 2011, data integration company working to take advantage of current technologies to provide not just better data integration but also better change management of modern data infrastructures. In many ways, they’re similar to another company, WhereScape, which I discussed last year. Both are young and small, while the market is large and the need is great.
The presentation was given by Sanjay Vyas, CEO, and John Santaferraro, CMO. The introduction by Sanjay was one of the best from a small company founder that I’ve seen in a long time. He gave a brief overview of the company, its size, it’s global structure (with HQ in Charlotte, NC, and two offshore development centers). Then he went straight to what most small companies leave for last: He presented a case study.
My biggest B2B marketing point is that you need to let the market know you understand it. Far too many technical founders spend their time talking about the technology they built to solve a business problem, not the business problem that was addressed by technology. Mr. Vyas went to the heart of the matter. He showed the pain in a company, the solution and, most importantly, the benefits. That is what succeeds in business.
It also wasn’t an anonymous reference, it was Scotiabank, a leading Canadian bank with a global presence. When a company that large gives a named reference to a startup as small as is Diyotta, you know the firm is happy.
John Santaferraro then took over for a bit with mostly positive impact. While he began by claiming a young product was mature because it’s version 3.5, no four year old firm still working on angel investments has a fully mature product. From the case study and what was demo’d later, it’s a great product but it’s clear it’s still early and needs work. There’s no need to oversell.
The three main markets John said Diyotta aims at are:
While the other two are important, I think it’s the middle one that’s the sweet spot. They focus on metadata to abstract business knowledge of sources and targets. While many IT organizations are experimenting with Hadoop and big data, getting a better understanding and improved control over the entire EDW and data infrastructure as big data is added and new mainline techniques arrive is where a lot more immediate pain exists.
Another marketing miss that could have incorporated that key point was when Mr. Santaferrero said that the old ETL methods no longer work because “having a server in the middle of it … doesn’t exist anymore.” The very next slide was as follows.
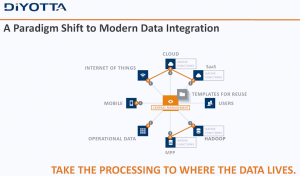
Diyotta still seems to have a server in the middle, managing the communications between sources and targets through metadata abstraction. The little “A’s” in the data extremities are agents Diyotta uses to preprocess requests locally to optimize what can be optimizes natively, but they’re still managed by a central system.
The message would be more powerful by explaining that the central server is mediating between sources and targets, using metadata, machine learning and other modern tools, to appropriately allocate processing at source, in the engine or in the target in the most optimal way.
While there’s power in the agents, that technology has been used in other aspects of software with mixed results. One concern is that it means a high need for very close partnerships with the systems in which the agents reside. While nobody attending the live presentation asked about that, it’s a risk. The reason Sanjay and John kept talking about Netezza, Oracle and Teradata is because those are the firms whose products Diyotta has created agents. Yes, open systems such as Hadoop and Spark are also covered, but agents do limit a small company’s ability to address a variety of enterprises. The company is still small, so as long as they focus on firms with similar setups to Scotiabank, they have time to grow, to add more agents and widen their access to sources; but it’s something that should be watched.
On the pricing front, they use pricing purely based on the hub. There’s no per user or per connector pricing. As someone who worked for companies that used pricing that involved connectors, I say bravo! As Mr. Vyas pointed out, their advantage is how they manage sources and targets, not which ones you want them to access. While connecting is necessary, it’s not the value add. The pricing simplifies things and can save money compared with many more complex pricing schemes that charge for parts.
The final business point concerns compliance. An analyst in the room (Sorry, I didn’t catch the name) asked about Sarbanes-Oxley. The answer was that they don’t yet directly address compliance but their metadata will make it easier. For a company that focuses on metadata and whose main reference site is a major financial institution, it would serve their business to add something to explicitly address compliance.
Diyotta is a young company addressing how enterprises can leverage big data as target and source alongside the existing infrastructure through better metadata management and data access. They are young and have many of the plusses and minuses that involves. They have some great technology but it’s early and they’re still trying to figure out how to address what market.
The one major advantage they have, given what I’ve seen in only a two hour presentation, is Sanjay Vyas. Don’t judge a startup on where they are now or where you think they need to be. Judge them on whether or not management seems capable of getting from point A to point B. Listening to Mr. Vyas, I heard a founder who understands both business and technology and will drive them in the direction they need to go.
A recent presentation by IBM at the BBBT was interesting. As usual, it was more interesting to me for the business information than the details. As unusual, they did a great job in a balanced presentation covering both. While many presentations lean too heavily in one direction or the other, this one covered both sides very well.
The main presenter was Harriet Fryman, VP of Marketing, IBM Analytics Platform. Adding information during the presentation were Steven Sit, Director of Product Management, Open Source Based Analytics Systems, and Steve Beier, Program Director, Spark Technology Center.
The focus of the talk was IBM’s commitment to Apache Spark. Before diving deep into the support, Ms. Fryman began by talking about business’ evolving data needs. Her key point is that “we all do data hording,” that modern technologies are allowing us to horde far more data than ever before, and that better ways are needed to get value out of the data.
She then proceeded to define three key aspects of the growth in analytics:
The second two overlap, as the ability to analyze large volumes of data in near real-time means a need to have systems do more analysis. The following slide also added to IBM’s picture of the changing focus on higher level information and analytics.
The presentation did go off on a tangent as some analysts overthought the differences in the different IBM groups for analytics and for Watson. Harriet showed great patience in saying they overlap, different people start with different things and internal organizational structures don’t impact IBM’s ability to leverage both.
The focus then turned back to Spark, which IBM sees as the unifying layer for data access. One key issue related to that is the Spark v Hadoop debate. Some people seem to think that Spark will replace Hadoop, but the IBM team expressed clear disagreement. Spark is access while Hadoop is one data structure. While Hadoop can allow for direct batch processing of large jobs, using Spark on top of Hadoop allows much more real time processing of the information that Hadoop appropriately contains.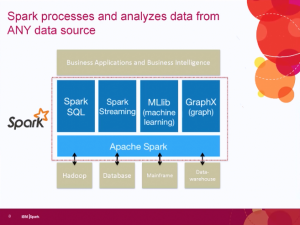
One thing on the slide that wasn’t mentioned but links up with messages from other firms, messages which I’ve supported, is that one key component, in the upper left hand corner of the slide, is Spark SQL. Early Hadoop players were talking about no-SQL, but people are continuing to accept that SQL isn’t going anywhere.
Well, most people. At least fifteen minutes after this slide was presented, an attending analyst asked about why IBM’s description of Spark seemed to be similar to the way they talk about SQL. All three IBM’ers quickly popped up with the clear fact that the same concepts drive both.
While the team continued to discuss Spark as a key business imitative, Claudia Imhoff asked a key question on the minds of anyone who noticed huge IBM going to open source: What’s in it for them? Harriet Fryman responded that IBM sees the future of Spark and to leverage it properly for its own business it needed to be part of the community, hence moving SystemML to open source. Spark may be open source, but the breadth and skills of IBM mean that value added applications can be layered on top of it to continue the revenue stream.
Much more detail was then stated and demonstrated about Spark, but I’ll leave that to the more technical analysts and vendor who can help you.
One final note put here so it didn’t distract from the main message or clutter the summary. Harriet, please. You’re a great expert and a top marketing person. However, when you say “premise” instead of “premises,” as you did multiple times, it distracts greatly from making a clear marking message about the cloud.
IBM sees the future of data access to be Apache Spark. Its analytics group is making strides to open not only align with open source, but to be an involved player to help the evolution of Spark’s data access. To ignore IBM’s combined strength in understanding enterprise business, software and services is to not understand that it is a major player in some of the key big data changes happening today. The IBM Spark initiative isn’t a marketing ploy, it’s real. The presentation showed a combination of clear business thought and strategy alongside strong technical implementation.
The most recent TDWI webinar had a guest analyst, David Loshin of Knowledge Integrity. The presentation was sponsored by Liaison and that company’s speaker was Manish Gupta. Given that Liaison is a cloud provider of data integration, it’s no surprise that was the topic.
David Loshin gave a good overview of the basics of data integration as he talked about the growth of data volumes and the time required to manage that flow. He described three main areas to focus upon to get a handle on modern integration issues:
Data curation is the organization and management of data. While David accurately described the necessity of organizing information for presentation, the one thing in curation that wasn’t touched upon was archiving. The ability to present a history of information and make it available for later needs. That’s something the rush to manage data streams is forgetting. Both are important and the later isn’t replacing the former.
The most important part of the orchestration Mr. Loshin described was in aligning information for business requirements. How do you ensure the disparate data sources are gathered appropriately to gain actionable insight? That was also addressed in Q&A, when a question asked why there was a need to bother merging the two distinct domains of data integration and data management. David quickly pointed out that there was no way not to handle both as they weren’t really separate domains. Managing data streams, he pointed out, was the great example of how the two concepts must overlap.
Data monitoring has to do with both data in motion, as in identifying real-time exceptions that need handling, and data for compliance, information that’s often more static for regulatory reporting.
The presentation then switched to Manish Gupta, who proceeded to give the standard vendor introduction. It’s necessary, but I felt his was a little too high level for a broader TDWI audience. It’s a good introduction to Liaison, but following Mr. Loshin there should have been more detail on how Liaison addresses the points brought up in the first half of the presentation – Just as in a sales presentation, a team would lead with Mr. Gupta’s information, then the salesperson would discuss the products in more detail.
Both presenters had good things to say, but they didn’t mesh enough, in my view, and you can find out far more talking to each individually or reading their available materials.
The Internet of Things (IOT) is something more and more people are considering. Wednesday’s TDWI webinar topic was “Stream Processing: Streaming Data in Real Time, in Memory,” and the event was sponsored by both SAP and Intel. Nobody from Intel took part in the presentation. Given my other recent post about too many cooks, that’s probably a good thing, but there was never a clear reason expressed for Intel’s sponsorship.
Fern Halper began with overview of how TDWI is seeing data streaming progress. She briefly described streaming as dealing with data while still in motion, as opposed to data in warehouses and other static structures. Ms. Halper then proceeded to discuss the overlap between event processing, complex event processing and stream mining. The issue I had is that she should have spent a bit more time discussing those three terms, as they’re a bit fuzzy to many. Most importantly, what’s the difference between the first two?
The primary difference is that complex event processing is when data comes from multiple sources. Some of the same things are necessary as ETL. That’s why the in-memory message was important in the presentation. You have to quickly identify, select and merge data from multiple streams and in-memory is the way to most efficiently accomplish that.
Ms. Halper presented the survey results about the growth of streaming sources. As expected, it shows strong growth should continue. I was a bit amused that it asked about three categories: real-time event streams, IOT and machine data. While might make sense to ask the different terms, as people are using multiple words, they’re really the same thing. The IoT is about connecting things, which interprets as machines. In addition, the main complex events discussed were medical and oil industry monitoring, with data coming from machines.
Jaan Leemet, Sr. VP, Technology, at Tangoe then took over. Tangoe is an SAP customer providing software and services to improve their IT expense management. Part of that is the ability to track and control network usage of computers, phones and other devices, link that usage to carrier billing and provide better cost control.
A key component of their needs isn’t just that they need stream processing, but that they need stream processing that also works with other less dynamic data to provide a full solution. That’s why they picked SAP’s Even Stream Processor – not only for the independent functionality but because it also fits in with their SAP ecosystem.
One other decision factor is important to point out, given the message Hadoop and other no-SQL folks like to give. SAP’s solution works in a SQL-like language. SQL is what IT and business analysts know, the smart bet for rapid adoption is to understand that and do what SAP did. Understand the customer and sales becomes easier. That shouldn’t be a shock, but technologists are often too enamored of themselves to notice.
Neil McGovern, Sr. Director, Marketing, at SAP gave the expected pitch. It was smart of them to have Jaan Leemet go first and it would have been better if Mr. McGovern’s presentation was even shorter so there would have been more time for questions.
Because of the three presenters, there wasn’t time for many questions. One of the few question for the panel asked if there was such a thing as too much data. Neil McGovern and Jaan Leemet spent time talking about the technology of handling lots of streaming data, but only in generalities.
Fern Halper turned it around and talked about the business concept of too much data. What data needs to be seen at what timeframe? What’s real-time? Those have different answers depending on the business need. Even with the large volume of real-time data that can be streamed and accesses, we’re talking about clustered servers, often from a cloud partner, and there’s no need to spend more money on infrastructure than necessary.
I would have liked to have heard a far more in-depth discussion about how to look at a business and decide which information truly requires streaming analysis and which doesn’t. For instance, think about a manufacturing floor. You want to quickly analyze any data that might indicate failures that would shut down the process, but the volumes of information that allow analysis of potential process improvements don’t need to be analyzed in the stream. That can be done through analysis of a resultant data store. Yet all the information can be coming across the same IoT feed because it’s a complex process. Firms need to understand their information priority and not waste time and money analyzing information in a stream for no purpose other than you can.