Yesterday, Tableau Software held an analyst briefing. It wasn’t a high level one, it was really just a webinar where they covered some product futures under NDA. However, it was very unclear what was NDA and what wasn’t. When they discussed things announced at the most recent Tableau Conference in Seattle, that’s not NDA, but there was plenty of future discussed, so I’ll walk a fine line.
The first news is to cover their Third Quarter announcement from the beginning of the month. This was Tableau’s first quarter of over $100 million in recognized revenue. It’s a strong showing and they’re justifiable proud of their consistent growth.
Ajay Chandrdamouly, Analyst Relations, also said that the growth primarily results from a Land and Expand strategy, beginning with small jobs in departments or divisions, driven by business needs, then expanding into other organizations and eventually into a corporate IT account position. However, one interesting point is an expansion mentioned later in the presentation by Francois Ajenstat, Product Management, while giving the usual case studies seen in such presentations. He did a good job of showing one case study that was Land and Expand, but another began as a corporate IT account and usage was driven outward by that. It’s an indication of the maturity of both Tableau and the business intelligence (BI) market that more and more BI initiatives are being driven by IT at the start.
Francois’ main presentation was about releases, past and future. While I can’t write about the later, I’ll mention one concern based on the former. He was very proud about the large number of frequent updates Tableau has released. That’s ok in the Cloud, where releases are quickly rolled into the product that everyone uses. However, that’s a risk in on-premises (yes, Francois, the final S is needed) installations in the area of support. How long do you support products and how do you support them is an issue. Your support team has to know a large number of variations to provide quick results or must investigate and study each time, slowing responses and possibly angering customers. I asked about the product lifecycle and how they managed to support and to decide sunsetting issues, but I did not get a clear and useful answer.
The presentation Mr. Ajenstat gave listed six major focus themes for Tableau, and that’s worth mentioning here:
- Seamless Access to Data
- Analytics & Statistics for Everyone
- Visual Analytics Everywhere
- Storytelling
- Enterprise
- Fast, Easy, Beautiful
None of those is a surprise, nor is the fact that they’re trying to build a consistent whole from the combination of foci. The fun was the NDA preview of how they’re working on all of those in the next release. One bit of foreshadowing, they are looking at some issues that won’t minimize enterprise products but will be aimed at a non-enterprise audience. They’ll have to be careful how they balance the two but expansion done right brings a wider audience so can be a good thing.
The final presenter was Ellie Fields, Product Marketing, who talked more about solution than product. Tableau Drive is not something to do with storage or big data, it’s a poorly named but well thought out methodology for BI projects. Industry firms are finally admitting they need some consistency in implementation and so are providing best practices to their implementation partners and customers to improve success rates, speed implementation and save costs. Modern software is complex, as are business issues, so BI firms have to provide a combination of products and services that help in the real world. Tableau Drive is a new attempt by the company to do just that. There’s also no surprise that it uses the word agile, since that’s the current buzzword for iterative development that’s been going on long before the word was applied. As I’m not one who’s implemented BI product, I won’t speak to its effectiveness, but Drive is a necessity in the marketplace and Tableau Drive helps provide a complete solution.
Summary
The briefing was a technical analyst presentation by Tableau about the current state of the company and some of its futures. There was nothing special, no stunning revelations, but that’s not a problem. The team’s message is that the company has been growing steadily and well and that their plans for the future are set forward to continue that growth. They are now a mid-size company, no longer as nimble as startups yet don’t have the weight of the really large firms, they have to chart a careful path to continue their success. So far it seems they are doing so.


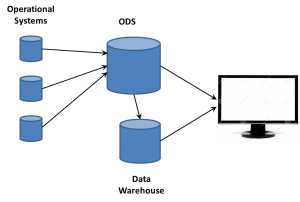
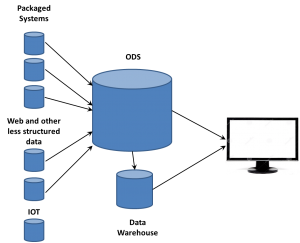 want to take ownership of concepts, especially those on the edge. So the folks working with these new data sources began talking about Big Data as somehow completely different than what came before. If that was the case, they needed to think of some term for the database where they dumped all the data extracted from web sites. Data Lakes became one term. We’ve heard data swamp and other attempts to create unique terms so a company can differentiate itself from others. However, there’s already a name.
want to take ownership of concepts, especially those on the edge. So the folks working with these new data sources began talking about Big Data as somehow completely different than what came before. If that was the case, they needed to think of some term for the database where they dumped all the data extracted from web sites. Data Lakes became one term. We’ve heard data swamp and other attempts to create unique terms so a company can differentiate itself from others. However, there’s already a name.