Tuesday’s TDWI webinar had a guest star: Claudia Imhoff. The topic was predictive analytics and the presentation was sponsored by SAP, so Pierre Leroux, Director of Product Marketing, SAP, also had his moment towards the end. Though the title was about predictive analytics, it’s best to view the presentation as an overview of the state of analytics, and there’s much more to discuss on that.
The key points revolved around a descriptive slide Ms. Imhoff presented to describe the changing analytics landscape.
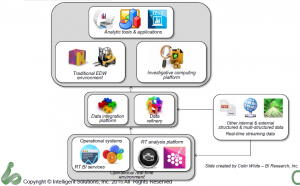
Claudia Imhoff described the established EDW information supply chain as being the left half of the diagram while the newer information, with web, internet of things (IOT) and other massive data sources adding the right hand side. It’s a nice, clean way of looking at things and makes clear that the newer data can still drive rather than eliminate the EDW.
One thing I’d say is missing is a good name for the middle box. Many folks call was Ms. Imhoff terms the Date Refinery a Data Lake or other similar rationalizations. My issue is that there’s really no need to list the two parts separate. In fact, there’s a need to have them seamlessly accessible as a whole, hence the growth of SQL for Hadoop and other solutions. As I’ve expressed before, the combination of the data integration and data refinery displayed are just the next generation of the ODS. I like the data refinery label, but think it more accurately applies to the full set of data described in the middle section of the diagram.
Claudia also described, the four types of analytics:
- Descriptive: What happened.
- Diagnostic: Why it happened.
- Predictive: What might happen.
- Prescriptive: What to do when it happens.
It’s important to understand the difference in analysis because each type of report needs to have a focus and an audience. One nit I have with her discussion of these was the comment that descriptive analytics are the least valuable. Rather, they’re the least strategic. If we don’t know what happened, we can’t feed the other types of analytics, plus, reporting requirements in so much of business means that understanding and reporting what happened remains very valuable. The difference is not how valuable, but in what way. Predictive and prescriptive analytics can be more valuable in the long term, but their foundation still resides on descriptive.
Not more with the Data Scientist…
My biggest complaint with our industry at large is still the obsession with the mythical data scientist. Claudia Imhoff spent a good amount of time on the subject. It’s a concept with super human requirements, with Claudia even saying that the data scientist might be the one with deep business knowledge. Nope. Not going to happen.
In Q&A, somebody brought up the point I always mention: Why does it have to be one person rather than a team. Both Claudia Imhoff and Pierre Leroux admitted that was more likely. I wish folks would start with that as it’s reasonable and logical.
I was a programmer as folks began calling themselves software engineers. I never liked that. The job wasn’t engineering but a blend of engineering and crafting. There was art. The two presenters continued to talk about the data scientist as having an art component, but still think that means the magical person is still a scientist. In addition, thirty year ago the developer was distanced much further from business, by development methods, technology and business practice. Being closer means, again, teamwork, with each person sharing expertise in math, coding, business and more to create a robust solution.
That wall has been coming down for years, but both technology and business are changing rapidly and are far more complex. The team notion is far more logical.
Business and Technology
The other major problem I had was a later slide and words accompanying it that implied it’s up to the business people to get on board with what the technologists are doing. They must find the training, they must learn that analytics are the answer to everything.
Yes, we’re able to provide better analytics faster to management than in the past. However, they’re not yet perfect nor will they be. Models are just that. As Pierre pointed out, models will never explain 100%.
Claudia made a great point earlier about one of the benefits of big data is to eliminate sampling and look at what the entire market is doing, but markets are still complex and we can’t glean everything. Technologists must get of the high horse and realize that some of the pushback from management is because the techies too often tend to dismiss intuition and experience. What needs to happen is for the messages to change to make it clear that modern analytics will help executives and line management make better decisions, not that it will replace their decision making.
In addition, quit making overly complex visualization that have great scientific relevance but waste time. The users do not need to understand the complexities of systems. If we’re so darned smart, we can distill the visualizations to things easier to comprehend so that managers can get the information, add it to all the other information and experience and make decision.
Technologists must adapt to how business runs as much as business must adapt to leverage technology.
Summary
The title of the presentation misrepresents the content. It was a very good presentation for understanding the high level landscape of the analytics information supply chain and it’s a discussion that needs to be held more often.
You’ll notice I didn’t say much about the demo by Pierre Leroux. That’s because of technical issues between demo and webinar software. However, both he and Claudia Imhoff took questions about the industry and market and gave thoughtful answers that should help drive the conversation forward.