Last Friday’s BBBT presentation was by Glen Rabie, CEO, and John Ryan, Product Marketing Director, from Yellowfin. I reviewed their 7.1 release webinar in late August but this was a chance to hear a longer presentation focused for analysts.
Their first focus was on the BARC BI Survey 14. One point is that they were listed as number one, by far, in how many sites are using the product in a cloud environment. That’s interesting because Yellowfin does not offer a cloud version. This is corporations installing their own versions on cloud servers.
A Tangent: Cloud v On-Premises?
That brings up an interesting issue. Companies like to talk about cloud versus on-premises (regardless of the large number of people who don’t seem to know to use the “s”) installations, but that’s not really true. Cloud can be upper case or lower. Upper case Cloud computing is happening in the internet, outside a company’s firewall. However, many server farms, both corporate owned and third party, are allowing multi-server applications to run inside corporate firewalls the same way they’d run outside. That’s still a cloud installation by the technical methodology, but it’s not in the Cloud. It’s on-premises in theory, since it’s behind the firewall.
Time for a new survey. We’re talking about multi-server, parallel processing applications verses single server technology. What’s a good name for that?
Back to Our Regularly Scheduled Diatribe
One bit of marketing fluff I heard is that they claim to be the first completely browser based UI. I’ve heard from a number of other vendors who have used HTML5 to provide pure browser interfaces, so I don’t know or care if they were first. The fact that they’re there is important, as is the usability of the interface. The later matters more. As I mentioned in the v7.1 review, they don’t hide that they’re focused on the business analyst rather than the end user, and for that target audience it is a good interface.
An important issue that points to a maturation of business intelligence in the market place was indicated by a statement John Ryan made about their sales. Yellowfin used to be almost exclusively based on sales to small pilot projects, then working to increase the footprint in their clients. He mentioned that they’ve seen a recent and significant increase in the number of leads that are coming into the funnel as full enterprise sales from the start. That’s both a testament to IT reviewing and accepting the younger BI companies and to Yellowfin’s increased visibility in the market.
“All About the Dashboard” and Data Governance
Glen and John repeatedly came back to the idea that they’re all about providing dashboards to the business user, focusing on letting technical people do discovery and the tough work then just addressing visualization for the end user. The idea that the technical people should do the detailed discovery and the business user show just look at things, slicing and dicing in a limited fashion, might be a reason they’re seeing more enterprise sales.
They seem to be telling IT that companies can get modern visualization tools while still controlling the end users. That’s still a priests at the temple model. That’s not all bad.
On one side, they’ll continue to frustrate end users by limiting access to the information they want to see. On the other side, many newer firms are all about access and don’t consider data governance. Yes, we want to empower business knowledge workers, but we also need to help companies with regulatory and contractual requirements for data governance.
Yellowfin seems to be walking a fine line. They have some great data governance capabilities built in, with access control and more. One very useful function is the ability to watermark reports as to their approved status within the company. It might seem minor, but helping viewers understand the level of confidence a firm has in certain analysis is clearly an advantage.
An interesting discussion occurred in the session and on Twitter about a phrase used in the presentation: Governed Data Discovery. Some analysts think it’s an oxymoron, that data discovery shouldn’t be governed or limited or it’s not discovery. I think it makes a lot of sense because of the need for some level of controls. Seeing all data makes no sense for many reasons, and governance is required. Certainly, too tight governance and control is a problem, but I like where Yellowfin seems to be going on that front.
But What About the Rest of BI?
As mentioned, Yellowfin is working to let analysts build reports and help knowledge workers consume reports. However, the reports are built from data. Where’s that come from? Who knows?
When I asked how they get the information, they clearly stated they weren’t interested in the back end of BI, not ETL, not databases. They’re leaving that to others. That’s a risk.
Glen Rabie pointed out, earlier in the presentation, that many of their newer clients are swap-outs of older BI technologies. For instance, he said two of his more recent clients in Japan had swapped out Business Objects for Yellowfin. Check the old Business Objects press releases from customers in the last couple of decades. The enterprise sales weren’t “Business Objects sells…” but rather “Business Objects and Informatica,” “Business Objects and Teradata,” etc. visualization is the end of a long BI process and enterprises want the full information supply chain.
As long as Yellowfin is both clear about its focus and prepared to work closely with other vendors in joint sales situations then it won’t be a problem as the company grows. They need to be prepared for that or they’ll slow the sales cycle.
Social Media Overthought
The final major point is about Yellowfin’s functionality for including social media within the product to enhance collaboration. While the basic concept is fine and their timeline functionality allows a team to track the evolution of the reports, I have two issues.
First, the product doesn’t link with other corporate-wide social tools. That means if a Yellowfin user wants to share something with someone who doesn’t need to use the tool, a new license is needed. I know that helps Yellowfin’s top line, but I think there should be some easy way of distributing new analysis for feedback from a wider audience without a full license.
Second, and much less important, is the mention of allowing people to vote on the reports. I was amused. It reminded me of a great quote from the late Patrick Moynihan, “Everyone is entitled to his own opinion, but not to his own facts.” I think the basic social tool in Yellowfin is very useful, but voting on facts seems a tad excessive.
Summary
Glen Rabie and John Ryan gave a great overview of Yellowfin, covering both the company’s strategy and the current state of product. Their visualization is as good as most others and they have some of the most advanced data governance capabilities in the BI industry.
There’s a lot of good going on down under. Companies wanting modern visualization tools should take a look, with one caveat. If you think that the power of modern systems means that functionality is clearly moving forward and should allow business users to do more than they have been able to do, Yellowfin might not match up with other firms. If you think that end users only want dashboards and want a good way of providing business workers with those dashboards, call now.

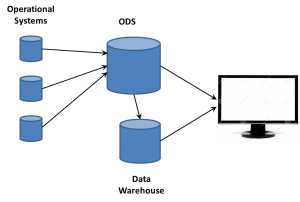
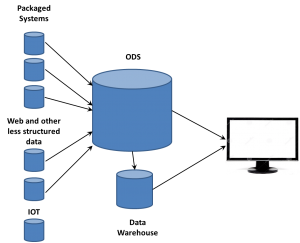 want to take ownership of concepts, especially those on the edge. So the folks working with these new data sources began talking about Big Data as somehow completely different than what came before. If that was the case, they needed to think of some term for the database where they dumped all the data extracted from web sites. Data Lakes became one term. We’ve heard data swamp and other attempts to create unique terms so a company can differentiate itself from others. However, there’s already a name.
want to take ownership of concepts, especially those on the edge. So the folks working with these new data sources began talking about Big Data as somehow completely different than what came before. If that was the case, they needed to think of some term for the database where they dumped all the data extracted from web sites. Data Lakes became one term. We’ve heard data swamp and other attempts to create unique terms so a company can differentiate itself from others. However, there’s already a name.