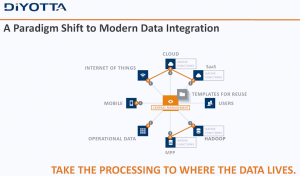
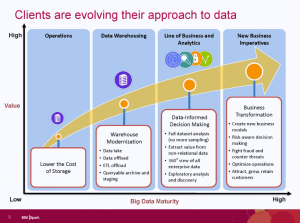
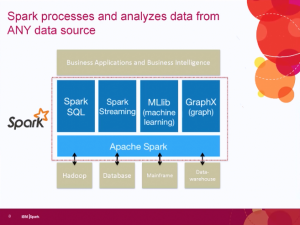
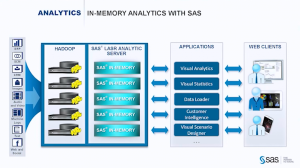
This week’s TDWI hosted webinar was about engaging business and, once again, it came from the standpoint of technologists rather than from business. There were some very good things said. However, until our industry stops thinking of business knowledge workers as children to be tutored and begins to think about them as people whose knowledge is the core of what we must encapsulate, we’ll continue to miss the mark and adoption of solutions will remain slow.
The main presenter was David Loshin, President of Knowledge Integrity. He began the presentation with a slide that describes his view of the definition of “data driven,” including three main points:
- Focus on turning data into actionable knowledge that can lead to increased corporate value.
- Aware of variance that can cause inconsistent interpretation.
- Coordination among data consumers to enforce standards for utilization.
We should all clearly understand that the first item is not new and was not created by the business intelligence (BI) industry. Business has always been data driven. What we’re able to do now is access far more data than ever before so that we can provide a more robust view of the corporation.
Inconsistent Data v Inconsistent Utilization
The second bullet is a core point. Mr. Loshin used a couple of example such as sales territory and other areas where definitions are fuzzy. One clear difference to me is one I directly experienced 25 years ago, and more directly addresses the visualization side of the BI conundrum. I was working for a major systems integrator (SI) and my client was, well, let’s just say it was a large, fruit based computing company.
A different SI had created an inventory system for the client’s manufacturing facility but the system was a failure though all the right data was in the system. The problem was that the reports were great for the accounting department, not for inventory and manufacturing. We interviewed the inventory team and then rewrote reports to address and present the information from their standpoint.
Too often, technologists get lost in the detailed data definitions and matching fields across data sources. That is critical, but it loses the big picture. Even when data is matched, different business people use data differently.
Which brings us to David Loshin’s third point. No, we don’t need to enforce exact standards for utilization. We need to ensure that the data each consumer refers to is consistent, but we must do a better job in understanding that different departments can utilize the exact same data in a variety of ways.
Business Drivers and Data Governance
David did get to the key issue a bit later, on a slide titled Operationalizing Business Policies. He points out that it’s critical to ensure that “Information policies model the data requirements for business policy.” This is key and should be bubbled up higher in the mindset of our industry. While I hear it mentioned often, it seems to be honored more in the breach.
Time was spent discussing the importance of understanding different users and their varying utilization of data. As I mentioned in the introduction, the solution to the new complexities then veers from addressing business needs to ignoring history. In a previous blog post, I discussed how many in the industry seem to be ignoring the lessons to be learned from the advent of the PC. Mr. Loshin seems to be doing that when he talks about empowering the business users to set their own usability rules. He splits IT and business in the following way:
- Business data consumers are accountable for the rules asserting usability for their views of the data.
- IT becomes responsible for managing the infrastructure that empowers the business user.
The issue I have with that argument is a phrase that didn’t appear in this webinar until Linda Briggs, the moderator, mentioned it in a poll question right before Q&A: Data Governance. Corporations are increasingly liable for how they control and manage information. It does not make sense to allow each user to define their own data needs in a void. Rather than allow for massively expanded and relatively uncontrolled access to data and then later have to contract access, as corporations had to regain a handle on what was being done on scattered desktop computers, BI vendors should be positioning data governance from the start.
Whether it’s by executive fiat, a cross-functional team, or some other method, companies need to clarify data governance rules. Often, IT is the best intermediary between groups, actively participating in data governance definition as an impartial observer and facilitator. It is then the job of IT to ensure that it provides as open access as possible to business workers given their needs and the necessity of following governance rules.
There was one question, during Q&A, on the importance of data governance. I thought David Loshin again understated its importance while Harald Smith, Director of Product Management at Trillium, the webinar sponsor, had the comment that “everyone is responsible for data governance.” That is my only mention of the sponsor, as I felt his portion of the presentation was a recitation of sound bites, talking points and buzz words that didn’t provide any value to the hour.
Summary
David Loshin has a clear view of engaging the business and gets a number of key things correct. However, that view is one of a technologist looking over a self-imagined bridge separating technology and business. There’s not a bridge separating IT and business. They overlap in many critical areas and both must learn from and work well with each other.