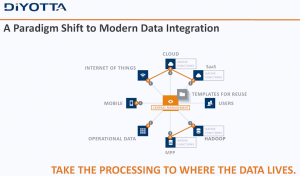
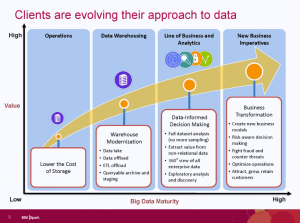
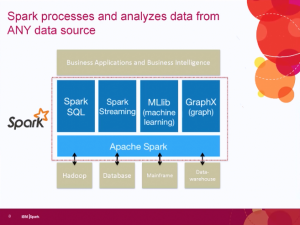
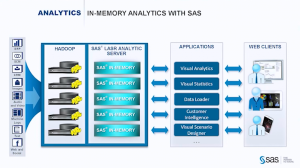
A recent Dataversity webinar was titled “Data Model is Data Governance.” All the right words were there but they were in the wrong order. The presenters were Robert S. Seiner, KIK Consulting, and David Hay, Essential Strategies. While Robert tried to push the title, David more accurately addressed the question “Is data modeling data governance?” Both he and I agree that the simple answer is no yet they overlap in important ways.
Data modeling is understand the data, and Mr. Hay described it in the context of business by referring to the Zachman Framwork, with the management’s overview of corporate information fitting Zachman’s first row then things diving deeper into technology as you move down the rows.
What I found interesting in a webinar with that title is the following definition slide:
When those are your definitions, it doesn’t make sense to talk about them as being the same. David Hay regularly pointed out the same thing during the presentation and I thought his points were very useful to people considering the issue. The slide very clearly and correctly points out the different but overlapping nature of the relationship between modeling, stewardship and governance.
Towards the end of the presentation, another comparison came up that I’ve previously discussed. The topic was whether or not data modeling is an art or a science. One flaw was that David Hay seemed to be implying that the only art was in the presentation of the models to management – physical art. His belief seemed to be that the modeling was pure science. I disagree as understanding data means understanding meaning, different people often mean different things when using terms and see different things from the same information, so art is needed to mediate solutions.
My biggest annoyance with the discussion was the word that should have been discussed never made an appearance. For the same reasons I’ve argued that programmers aren’t software engineers, modeling is neither one nor the other: It is a craft. It is a blend of the two worlds of art and science. I don’t know why people today seem upset to admit to modeling and most software work as a craft, the word doesn’t denigrate the work but describes it very well.
The final point made that I thought was great was in response to a question about when to start on logical and physical models, whether that should happen before you’ve defined your business models or they need to wait. Robert Seiner accurately used the old cliché, starting the other models before you understand your business model, the thing that drives business, is to follow the failed logic of “Ready! Fire! Aim!”
Given the title, I must also say that governance was given short shrift, basically mentioned only in definition, but I didn’t really mind. While the webinar was misnamed, it was a great conversation about the relationship between data modeling and business. The conversation between the two was worth the listen.