My latest article published in Search Data Management.
http://searchdatamanagement.techtarget.com/feature/Database-schemas-still-needed-despite-Hadoop-and-NoSQL-pretensions
My latest article published in Search Data Management.
http://searchdatamanagement.techtarget.com/feature/Database-schemas-still-needed-despite-Hadoop-and-NoSQL-pretensions
Tuesday’s TDWI webinar had a guest star: Claudia Imhoff. The topic was predictive analytics and the presentation was sponsored by SAP, so Pierre Leroux, Director of Product Marketing, SAP, also had his moment towards the end. Though the title was about predictive analytics, it’s best to view the presentation as an overview of the state of analytics, and there’s much more to discuss on that.
The key points revolved around a descriptive slide Ms. Imhoff presented to describe the changing analytics landscape.
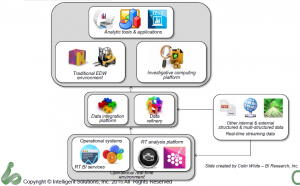
Claudia Imhoff described the established EDW information supply chain as being the left half of the diagram while the newer information, with web, internet of things (IOT) and other massive data sources adding the right hand side. It’s a nice, clean way of looking at things and makes clear that the newer data can still drive rather than eliminate the EDW.
One thing I’d say is missing is a good name for the middle box. Many folks call was Ms. Imhoff terms the Date Refinery a Data Lake or other similar rationalizations. My issue is that there’s really no need to list the two parts separate. In fact, there’s a need to have them seamlessly accessible as a whole, hence the growth of SQL for Hadoop and other solutions. As I’ve expressed before, the combination of the data integration and data refinery displayed are just the next generation of the ODS. I like the data refinery label, but think it more accurately applies to the full set of data described in the middle section of the diagram.
Claudia also described, the four types of analytics:
It’s important to understand the difference in analysis because each type of report needs to have a focus and an audience. One nit I have with her discussion of these was the comment that descriptive analytics are the least valuable. Rather, they’re the least strategic. If we don’t know what happened, we can’t feed the other types of analytics, plus, reporting requirements in so much of business means that understanding and reporting what happened remains very valuable. The difference is not how valuable, but in what way. Predictive and prescriptive analytics can be more valuable in the long term, but their foundation still resides on descriptive.
My biggest complaint with our industry at large is still the obsession with the mythical data scientist. Claudia Imhoff spent a good amount of time on the subject. It’s a concept with super human requirements, with Claudia even saying that the data scientist might be the one with deep business knowledge. Nope. Not going to happen.
In Q&A, somebody brought up the point I always mention: Why does it have to be one person rather than a team. Both Claudia Imhoff and Pierre Leroux admitted that was more likely. I wish folks would start with that as it’s reasonable and logical.
I was a programmer as folks began calling themselves software engineers. I never liked that. The job wasn’t engineering but a blend of engineering and crafting. There was art. The two presenters continued to talk about the data scientist as having an art component, but still think that means the magical person is still a scientist. In addition, thirty year ago the developer was distanced much further from business, by development methods, technology and business practice. Being closer means, again, teamwork, with each person sharing expertise in math, coding, business and more to create a robust solution.
That wall has been coming down for years, but both technology and business are changing rapidly and are far more complex. The team notion is far more logical.
The other major problem I had was a later slide and words accompanying it that implied it’s up to the business people to get on board with what the technologists are doing. They must find the training, they must learn that analytics are the answer to everything.
Yes, we’re able to provide better analytics faster to management than in the past. However, they’re not yet perfect nor will they be. Models are just that. As Pierre pointed out, models will never explain 100%.
Claudia made a great point earlier about one of the benefits of big data is to eliminate sampling and look at what the entire market is doing, but markets are still complex and we can’t glean everything. Technologists must get of the high horse and realize that some of the pushback from management is because the techies too often tend to dismiss intuition and experience. What needs to happen is for the messages to change to make it clear that modern analytics will help executives and line management make better decisions, not that it will replace their decision making.
In addition, quit making overly complex visualization that have great scientific relevance but waste time. The users do not need to understand the complexities of systems. If we’re so darned smart, we can distill the visualizations to things easier to comprehend so that managers can get the information, add it to all the other information and experience and make decision.
Technologists must adapt to how business runs as much as business must adapt to leverage technology.
The title of the presentation misrepresents the content. It was a very good presentation for understanding the high level landscape of the analytics information supply chain and it’s a discussion that needs to be held more often.
You’ll notice I didn’t say much about the demo by Pierre Leroux. That’s because of technical issues between demo and webinar software. However, both he and Claudia Imhoff took questions about the industry and market and gave thoughtful answers that should help drive the conversation forward.
Yesterday’s TDWI webinar was sponsored by Liaison Technologies, who did the same thing last year. It’s a push for another acronym. While the acronym isn’t needed, the concept is. Data Platform as a Service is just using the cloud to help with data integration. Gosh, complex, ‘eh? I think it’s the natural progression of technology and business, it’s just data management on the cloud. But forget the marketing, let’s talk about the concept.
The presentation’s first half was delivered by Phillip Russom. He started with some very trivial level setting but then quickly got to a key point. If you’ve been around for a while, you remember Best of Breed. That’s when each vendor focused product company, somewhere in the information supply chain, talked about their openness and how you could piece together a solution from different vendors. That made sense at the time, since many companies were each creating the early version of parts of a full solution.
As Phillip pointed out, times have changed. We now better understand business needs, have learned more about coding the requirements and can access far better hardware than we had fifteen years ago. That means IT is looking for what they couldn’t find back then: An integrated solution from a single or a far more limited number of vendors. They want something simpler than a hodgepodge of multiple systems.
The advantages of the cloud aren’t specific to data management. One very key business driver that was minimized in Mr. Russom’s presentation but brought out later by Patrick Adamiak during his presentation then revisited by both in the Q&A is capex versus opex – something often ignored by technical folks. Having your own hardware and data center is not just costly, it’s part of capital expenditure. Service contracts with a cloud vendor are operational expenses. That means the CxO suite and Board are often happier with that because it’s not as locked it and creates flexibility in the corporate financial picture.
One nit I had with Mr. Russom’s presentation was his statement that cloud is another architecture, like client/server or the web. The cloud and web are client server, that’s not the issue. It’s another architecture in two other key aspects: The already mentioned capex/opex divide, and the way it changes a software vendor’s ability to manage and update their software in comparison to on-premises installations.
One caution he gave that needed more explanation for folks new to the cloud was when Mr. Russom mentioned that you need to ask about the elasticity of the cloud implementation. For those who might not have heard the term, elasticity is the ability to grow or shrink cloud resources in order to match processing demands. In other words, if you get a big data dump from another source, can you quickly access more disk space? Or, from the Web side of the house: You’re hosting a big event or making a major announcement on your Web site: Can site resources be replicated quickly to handle the additional load then released when no longer needed?
I was impressed by the fact that capex was mentioned on Patrick Adamiak’s first slide. Cloud technology has multiple advantages that can be communicated to IT, but it’s the capex/opex issue that will help close the deal in an enterprise setting. Liaison seems to understand the need to blend technical and business messages.
However, most of Mr. Adamiak’s presentation seemed to be about justifying the new acronym. The main slide compared dPaaS with other supposed solutions without admitting there’s really a lot of overlap between them. The columns weren’t as different as he’d like them to be.
His company slides didn’t seem any different than those I’ve seen from the many other firms in the space. Forget all of that, it was in a short webinar with TDWI, so he had limited time.
The fact is that Liaison claims they are where the market is going. They are vertically integrating the information supply chain while leveraging the cloud for its business and technology advantages. For those in IT looking to simplify their world, Liaison is a company that should be investigated.
The most recent BBBT presentation was from Dell Software. Peter Evans, Sr. Integrated Solutions Development Consultant , and Steven Phillips, Product Marketing Manager – Big Data & Analytics, gave us an overview of Dell’s architecture for addressing business intelligence (BI). 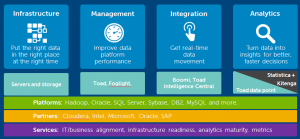
What they’re working to accomplish is, no surprise, ensure that Dell’s hardware is able to be present throughout the BI supply chain. For that, they’re working to be application agnostic, though they mislabel it as “no lock-in.” What they’re saying is you can change your software vendors and Dell will still be there. There’s no addressing true lock-in, the difficulty in changing one software vendor to another based on level of openness to data in systems and other costs of moving.
One marketing nit that caught a number of us was Peter’s early claim that Dell is “probably the third largest software company in the world.” Right… First, as a now privately held company, we have no way to confirm that. Second, I’m not sure if he knows just how much revenue is needed to be near the top of that list.
Far too many young firms are overselling BI as something that will let business “avoid IT.” That’s not only impossible, it wouldn’t make sense if it was possible. IT has a clear place in organizing infrastructure, providing consistency, helping with compliance and doing other things a central organization should do.
Dell has started with IT. They’re used to dealing with IT and their solution is focused on helping IT enable business. What’s not clear is how well they can do such a thing in the new world. They’ve pieced a lot of different applications into an architecture and that would seem to require heavy IT involvement in much of what’s being provided.
On the good side, that knowledge means they better understand true enterprise business needs. Unlike many vendors, Dell has regulatory and statutory compliance at the forefront, very clear in its marketechture slides. While most companies understand they have to mention compliance, it’s usually people dealing with corporate business groups such as IT and legal who understand just how critical compliance is.
Neither Peter Evans nor Steven Phillips spoke clearly to the business user, the want for speed and flexibility for them. While younger companies need to move more to addressing the importance of IT, Dell needs to more strongly focus on the business customer, the ones who are often in charge of the BI and related software projects and spending.
The technical piece that stuck with me the most was the discussion of Boomi Suggest. Boomi is Dells integration tool. Within it, there’s a cloud-based tool called Boomi Suggest. If users subscribe to it, the product tracks data linkages and the de-natured information is kept to help other customers more quickly map data sources and targets.
Mr. Evens says that Boomi Suggest has a database that now contains more than 16 million links. The intelligence on top to that then is able to provide a 92% accuracy rate in analyzing new links. The time savings that alone suggests is a major decision driver that should not be overlooked.
While the case study didn’t address enough of the end user issues of timeliness, flexibility and more, it was a very interesting case study from an inclusive standpoint. The Dell team focused on asthma case management to show the breadth of data sources, the complexity of analytics and a full process that could be generalized from the healthcare sector in order to support their full platform message.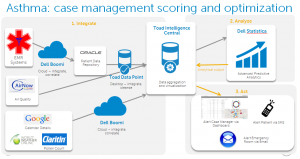
As you can see, they are doing a lot of things with a variety of information, but they’re also doing it with a variety of products.
Dell’s decades of working with IT has helped it look at BI with a more complex eye that can address many of IT’s concerns. What we saw was an almost completely IT solution and message. While BI focused companies are going to have to move down and address important IT messages, Dell must go in the opposite direction. Unless the team can broaden their message to address the solution to more business teams, Dell’s expansion in the market will be severely limited because it’s the business groups that write the checks.
The presentation shows a great start. However, the questions are if Dell can simplify the architecture to make it less complex, potentially by merging a number of their products, and whether or not they can learn about those folks they don’t have a history of directly understanding: The business user. If they can do that, the start will expand and Dell Software can help in the BI market.
The most recent BBBT presentation was by Looker. Lloyd Tabb, Founder & CTO, and Zach Taylor, Product Marketing Manager, showed up to display yet another young company’s interesting technology.
Looker’s technology is an application server that sits above relational databases to provide faster, more complex queries. They’ve developed their own language, LookML to help with that. That’s no surprise, as Lloyd is a self-described language guy.
It’s also no surprise that the demos, driven by both Lloyd and Zach, were very coding heavy. Part of the reason that very technical focus exists is, as Mr. Tabb stated, that Looker thinks there are two groups of users: Coders who build models and business managers who use the information. There is no room in that model for the business analyst, the person who understands who to communicate a complex business need to the coders and how to help the coders deliver something that is accessible to and understandable by the information consumer.
How the bifurcation was played out in the demonstration was through an almost exclusive focus on code, code and more code, with a brief display of some visualization technology. The former was very good while the later wasn’t bad but, to fit with their mainly technology focus, had complex visualizations without good enough legends – they were visualizations that would be understood by technical people but need to be better explained for the business audience they claim to address.
As an early stage company, that’s ok. The business intelligence (BI) market is still young and very fragmented. You can get different groups in large companies using different BI tools. While Looker talks about 300 customers, as with most companies of their size it could only be those small groups. If they’re going to grow past those groups, they need to focus a bit more in how to better bridge technology and business.
They also have a good start in attracting the larger market because they support both cloud and on-premises systems. The former market is growing while the later isn’t going away. Providing the ability for their server to run either place will address the needs of companies on either side of the divide.
One key to their system is they don’t move data. It stays resident on the source systems. Those could be operational systems, data warehouses, an ODS or whatever. What they must have is SQL. When asked about Hadoop and other schema-on-write systems, the Looker team stated they are an RDMS based application but they’ll work on anything with SQL access. I have no problem with the technology, but they need to be very clear about the split.
SQL came from the relational world, but as they pointed out in an aside, it isn’t limited to that. They should drop the RDMS message and focus on SQL. As Lloyd Tabb said, “SQL is the right abstraction.” What I don’t know if he understands, being focused on technology and having those biases, is it isn’t the right abstraction because of some technical advantage but because it’s the major player. McDonalds isn’t the best burger because it has the most stores. SQL might not be the best access method, but it’s the one business knows and so it’s the one the newer database companies and structures can’t ignore.
Last year, the BBBT heard from multiple companies including Actian and EXASOL, companies focused on providing SQL access to Hadoop. That’s as important as what Looker is doing. The company that manages to do both well with jump ahead of the pack.
Looker is a good, young company with some technical advantages that can greatly improve the performance of SQL queries to business databases and provides a basic BI front end to display the results. I’m not sure they have the resources to focus on both, and I think the former have the clearest advantage in the marketplace. Unless they have more funding and a strong management team that can begin to better understand the business side of the market, they will have problems addressing the visualization side of BI. They need to keep improving their engine, spread it to access more data sources, and partner with visualization companies to provide the front end.
Tuesday saw a rare, mid-week presentation at the BBBT. Silwood Technology, an Ascot, UK, company sent people to Boulder to present their technology. Roland Bullivant, Sales and Marketing Director, and Nick Porter, Technical Director (and a co-founder) were the presenters.
Silwood Safyr is focused on helping IT understand the metadata in their major packaged enterprise systems, primarily from SAP and Oracle with a recent addition of Salesforce. As those familiar with the enterprise application space know, there are a lot of tables in SAP and Oracle and documentation has never been, shall we say, close to perfect. In addition, all customers of those systems customize the applications, thereby making the metadata more difficult to understand. Safyr does a very good job at finding the technical metadata.
Let me make that clear: Technical metadata. The tables, indices and their relations are what is found. That’s extremely valuable, but not the full picture. Business metadata is not managed. I’ll discuss that in more detail below.
The company, as expected from European companies, uses partners rather than direct sales for its primary sales channel. In addition, they OEM white label products through IBM, CA and other firms. All told, Roland Bullivant says that 70% of their customers are via reseller channels. Also as expected, they still remain backline support for those partners.
As mentioned above, Safyr captures the database structure metadata. As Roland so succinctly put it, “The older packages weren’t really built with the outside world in mind.” The internal structures aren’t pretty and often aren’t easily accessible. However, that’s not the only difficulty in understanding an enterprise’s data structures.
Salesforce has a much simpler data structure, intentionally created to open the information to the ecosystem of partner applications that then grew up around the application. Still, as Mr. Bullivant pointed out, there are companies in Europe that have 16 or more customized versions in different countries or divisions, so understanding and meshing those disparate systems in order to build a full enterprise data model isn’t easy. That’s where Safyr helps.
Silwood Safyr is a great leap forward from having nothing, but there’s still much missing. While they build a data model, there’s not enough intelligence. For instance, they leave it to their users to figure out which tables are production and which are duplicates or other tables used just for performance. Sure, a table with zero rows usually means either a performance table or an unlocked app segment, but that’s left for the user rather than flagging, filtering and indicating any knowledge of the application and data structures.
Also, as mentioned above, there’s no business intelligence (gosh, where’d that word come from?). There’s nothing that lets people understand the business logic of the applications. That’s why this is a pure IT tool. The structures are just described in technical terms, exported to data modeling tools (a requirement for visualization, ERwin was used in the demo but they work with others ) and then left to the analysts to identify all the information need to clarify which tables are needed for which business purpose or customer.
One way to start working on that was indicated in Nick Porter’s demo. He showed that Safyr is good at not just getting table names, but also in accessing descriptive names and other metadata about the tables. That’s information needs to be leveraged to help prepare the results for use by people on the business side of the organization.
The main hole I see in the business links from the last section: The lack of emphasis on business knowledge. For instance, there’s a comparison function to analyze metadata between databases. However, as it’s purely on a technical level, it’s limited to comparing SAP with SAP and Oracle with Oracle. Given that differences in versions of those products can be significant, I’m not even sure how well that works across major version releases.
Not only do global enterprises have multiple versions of one vendor, they have SAP on one continent, Oracle in another and might acquire a new company that is using Salesforce. That lack of an ability to link business layers means that each package is working in a void and there’s still a lot of work required to build a coherent global picture.
Another part of their growth need is my usual soapbox. When the Silwood team was talking about how they couldn’t figure out why they weren’t growing as fast as they should, Claudia Imhoff beat me to the punch. She mentioned marketing. They’d earlier pointed out they don’t spend much on marketing and she quickly pointed out that’s a problem. This isn’t Field of Dreams, they won’t come just because you build it. Silwood marketing basics are good, with a lack of visible case studies being one hole, but they’re not pushing their message out through the channels.
Silwood Safyr is a good core product to help IT automate the documentation of data models in packaged enterprise software. It’s a product that should be of interest to every large enterprise using complex applications such as those by Oracle and SAP, or even multiple versions of simple databases such as Salesforce. However, there are two things missing.
The most important missing piece in the short term is the marketing necessary to help their resellers better understand benefits both they and the end customer receive, to improve interest in reselling and to shorten sales cycles.
The second is to look long term at where they can grow the business. My suggestion is to better work with business logic within and across applications vendors. That’s the key way they’ll defend their turf against the BI vendors who are slowly moving downstream to more technical data access.
The reason people want to understand data models isn’t out of curiosity, it’s to better understand business. Silwood has a great start in aiding enterprises in improving that understanding.
Last Friday’s BBBT presentation by an ensemble cast from Rocket Software was interesting, in both good and bad meanings of that word. They have some very interesting products that address the business intelligence (BI) industry, but they also have some confusion.
Bob Potter, SVP and GM, Business Intelligence, opened the presentation by pointing out that Rocket has more than $300 million (USD) in annual revenue yet many tech folks have never heard of them. One reason for the combination is they’ve done a good job in balancing both build and buy decisions to provide niche software solutions in a variety of places and on a number of platforms. Another is a strong mainframe focus. The third is that they don’t seem to know how to market. Let’s focus on just the two products presented to demonstrate all of these.
Most of the presentation was focused on Rocket Data Virtualization (DV). There are two issues it addressed. The first is accessing data from multiple sources without the need to first build a data warehouse. DV is the foundation of what was first thought of as the federated or virtual data warehouse. It’s useful. Gregg Willhoit, Managing Director, Research & Development, gave a good overview of DV and then delved into the product.
Rocket Data Virtualization is a mainframe resident product to enhance data virtualization, running on IBM z. While this has the clear market limit of requiring a company large enough to have a mainframe, it’s important to consider this. There are still vast amounts of applications running on mainframes and it’s not just old line Cobol. Mainframes run Unix, Linux and other OS partitions to leverage multiple applications.
An important point was brought up when Gregg was asked about access to the product. He said that Rocket is working with other BI industry partners, folks who provide visualization, so that they can access the virtualized data.
However, if you want to know more about the product, good luck. As I’ll discuss in more detail later, if you go to their site you’ll find all marcom fluff. It’s good marcom fluff, but driving deeper requires downloads or contacting sales people. That doesn’t help a complex enterprise sale.
The presentation was turned over to Doug Anderson, Solutions Engineer, for a look at their unreleased product Rocket Discover. It’s close, in beta, but it’s not yet out.
As the name implies, Rocket Discover is their version of a visualization tool. It’s a very good, basic tool that will compete well in the market except for two key things. The first is that they claimed Rocket is aiming at “high level executives” and that’s not the market. This is a product for business analysts. Second, while it has the full set of features that modern analysts will want, it’s based on a look and feel that’s at least a decade old.
On the very positive side, they do have a messaging feature built in to help with collaboration. It needs to grow, but this is a brand new product and they have seen where the market is going and are addressing it.
Another positive sign is this isn’t a mainframe product. It runs on servers (unspecified) and they’re starting with both on-premises and cloud options. This is a product that clearly is aimed at a wider market than they historically have addressed.
While they have understood the basics of the technology, the question is whether or not they understand the market. One teaser that shows that they probably don’t was brought up by another analyst who pointed out that Doug and others were often referring to the product as just Discover. Oracle has had a Discover product for many years. While Rocket might not have seen it on the mainframe, there will be some marketing issues if the company doesn’t always refer to the product as Rocket Discover, and they might have problems anyway. Their legal and marketing teams need to investigate quickly – before release.
The product presentation and a Q&A session that covered more issues with even more folks from Rocket taking part, show the problems Rocket will have. As pointed out, the main reasons that so many people have never heard of Rocket is it sells very technical solutions to enterprise IT. Those are direct sales to a very technical audience. However, enterprise software is more than enterprise IT.
Enterprise software such as ERP, CRM, SFA and, yes, BI, address business issues with technology. That means there will be a complex sales cycle involving people from different organizations, a cycle that’s longer and more involved than a pure sale to IT. I’m not sure that Rocket has yet internalized that knowledge. As mentioned above, their website is very fluffy, as if the thought is that you put something pretty (though I argue against the current fad of multiple bands requiring scrolling, it’s neither pretty nor easy to use) with mission and message only, then you quickly get your techies talking directly to their techies, is the way you sell. Perhaps when talking with techies only, but not in an enterprise sale.
That’s my biggest gripe about the software industry not understanding the need for product marketing. You must be able to build a bridge to both technical and business users with a mix of collateral and content that span the gap. I’m not seeing that with Rocket.
In addition, consider the two products and the market. DV is very useful and there are multiple companies trying to provide the capability. While Rocket’s knowledge of and access to mainframe data is a clear advantage, the fact the product only runs on mainframes is a very limiting competitive message. I understand they have tied their horses very closely to IBM, and it makes sense to have a z option, but to not provide multiple platforms or a way for non-mainframe customers to use their more general concepts and technologies will retard growth.
If their plan is to provide what they know first then spread to other platforms, it’s a good strategy; but that wasn’t discussed.
Both products, though, have the same marketing issue. Rocket needs to show that it understands it is changing from selling almost exclusively to enterprise IT and needs to create a more integrated product marketing message to help sell to the enterprise.
There’s also the issue of how to balance the messages for the two products. For Rocket Data Virtualization to succeed, it really does need to work with the key BI vendors. Those companies will wonder about Rocket’s dedication to them while Rocket Discover exists. Providing a close relationship with those vendors will retard Rocket Discover’s growth. Pushing both products will be walking a tightrope and I haven’t seen any messaging that shows they know it.
Rocket is a company that is very strong on technology that helps enterprise IT. Both Rocket Data Virtualization and Rocket Discover have the basics in place for strong products. The piece missing is an understanding of how to message the wider enterprise market and even the mid- and small-size company markets.
Rocket Data Virtualization is the product that has the most immediate impact with the clear differentiation of very powerful access to mainframe data and the product I think should make the more rapid entrant into its space. The question is whether or not they can spread platform support past the mainframe faster than other companies will realize the importance of mainframe data. In the short term, however, they have a great message if they can figure out how to push it.
Rocket Discover is a very good start for a visualization tool, but primarily on the technology side. They need to figure out how to jump forward in GUI and into predictive and other analytics to be truly successful going forward, but the market is young and they have time.
The biggest issue is if Rocket will learn how to market and sell in broader enterprise and SMB sales, both to better address the multiple buyers in the sales cycle and to better communicate how both products interact in a complex market place.
Rocket is worth the look, they just need to learn how to provide the look to the full market.
The latest TDWI Best Practices Report is concerned with Hadoop. Philip Russom is the author and the article is worth a read. However, it has the usual issue I’ve seen with many TDWI reports, very strong on numbers but missing the real business point. In journalism, there’s an expression called burying the lede, hiding the most important part of a story down in the middle. Mr. Russom gets his analysis correct, bit I think the priorities or the focus needs work. It’s a great report to use as a source by IT, it’s not a report for executives.
Why am I cranky? The report starts with an Executive Summary. The problem is that it isn’t aimed at executives but is something that lets technical folks think they’re doing well. It doesn’t tell executives why they should care. What are the business benefits? What are the risks? Those things are missing.
First, let’s deal with the humorous marketing number. The report mentions the supposedly astounding figure that “Hadoop clusters in production are up 60% in two years.” That’s part of the executive summary. You have to slide down into the body to understand that only 16% of respondents said they have HDFS production. It’s easy for early adopters to grow a small percent to a slightly larger small percentage, it’s much tougher to get a larger slice of the pie.
Philip Russom accurately deals with why it will take a bit for Hadoop to grow larger, but it does it past the halfway point of the article. Two things: Security and SQL.
Executives are concerned that technology helps business. Security ensures that intellectual property remains within the firm. It also ensures that litigation is minimized by not having breaches that could be outside regulatory and contractual requirements. Mr. Russom accurately discusses the security risks with Hadoop, but that begins down on page 18 and doesn’t bubble up into the executive summary.
So too is the issue of SQL. After writing about the problems in staffing Hadoop, the author gives a brief but accurate mention of the need to link Hadoop into the rest of a business’ information infrastructure. It is happening, as a sidebar comment points out with “Hadoop is progressively integrated into complex multi-platform environments.” However, that progress needs to speed up for executives to see the analytics from Hadoop data integrated into the big picture the CxO suite demands.
The report gives IT a great picture of where Hadoop is right now. As expected from a technical organization, it weighs the need, influence and future of the mystical data scientist too highly, but the generalities are there to help mid-level management understand where Hadoop is today.
However, I’ve seen multiple generations of technology come in, and Hadoop is still at an early adopter phase where too many proponents are too technical to understand what executives need. It’s important to understand risks and rewards, not a technical snapshot; and the later is what the report is.
IT should read this report as valuable insight to what the market is doing. It’s, obviously, my personal bias, but the summary is just that, a summary. It’s not for executives. It’s something that each IT manager will use for its good resources to build their own messages to their executives.
Let’s cut to the chase, this is another company with a very good product and no idea how to message. Unless they quickly figure out and communicate the right message, they’ll need to get ready for acquisition as an exit strategy.
Jinfonet is a company founded, it seems, to clone Crystal Reports in Java. Hence the awkward name. JReport, their product, is full featured and we’ll get to that, but the legacy name using report will leave them behind if that remains their focus.
The presentation was primarily by Dean Yao, Director of Marketing, with demo support brought by the able Leo Zhao, Senior Systems Consultant. However, the presentation indicated the message problem.
The name of the product is JReports, but at no time in the three hours did a report make an appearance. They showed two different analyst charts, Nucleus Research and EMA, of the business intelligence (BI) industry to show where they were placed. BI. Yet when asked about competition, Dean Yao repeatedly mentioned they didn’t compete against BI vendors but focused on reports.
Their own presentation begs to differ:
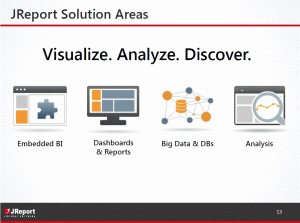
Notice that reports are a secondary feature of one focus.
What’s also good and bad is that Leo Zhao’s demonstrations showed a very richly featured product that does compete against the other vendors. The only major hole wasn’t in functionality, it’s that the rich set of visualizations weren’t as pretty as most of the competition. That is in part because they are self-funded with more limited resources and partly because they’re great techies who haven’t prioritized visualizations as they should.
OEM, in JInfonet’s business model, doesn’t only mean the product embedded in third party applications. Mr. Yao discussed how JReport is also regularly embedded in departmental IT applications. That is different than when companies use JReport as a standalone product.
Dean talked about how 30% of their business in recent years was direct, with the rest being OEM. At the same time, he mentioned that last year was around 50/50. That’s not a problem. What is an issue is that they don’t know why it was. Did sales focus on direct? Was one major direct client a large revenue outlier which skewed the results? They don’t seem to know.
That matters because the OEM and direct models are very different. With OEM, you let the other company deal with business messages. All you’re doing is presenting to them a good technical story and cost point compared do simpler products, a tiny segment of competition or doing nothing and losing out to their competitors.
Enterprise sales, on the other hand, require a focus on the end user, the folks using the products and the business issues they have. That is what’s missing from the presentation, their web site and the few pieces of collateral I reviewed.
One thing should also be said about the OEM to departments model. The cloud is changing the build v buy balance for many departments for the applications in which JReport is embedded, so I’m not sure how much longer this model will be of significant revenue.
Mr. Yao said they don’t do enterprise sales, but just sell to SMB and enterprise departments, so that means they’re not really competing against other BI vendors. A lot of the analysts on the call quickly jumped on that, pointed out that even one of the largest companies openly talks about its strategy of land and expand. “Just land” is not a long term strategy.
Right now the enterprise market is very fragmented, so there’s a space for a small company, but that won’t last long. Crystal Reports had a long run based on the technologies of the day, but it no longer is independent. Today, things are changing far more rapidly. The cloud is allowing BI firms to address small to global companies with similar products and the major players (and most smaller ones) are focused on that full business market.
Given the current product, JInfonet can go one of two ways. They can decide to completely focus on OEM, keep a technical message and just sell enterprise as it happens.
The other option, one I openly prefer, is that they realize that they have a very good product that does compete in the direct model and they need to focus more messaging. They can still provide to OEM, but that’s easier – it’s a subset of the full featured message.
The solution, though, resides in the folks who weren’t in Boulder: The founders. The company has been self-funded since 1998 and the founders are used to their control. I’ve seen companies fail because owners were unwilling to see that times have changed. They mistakenly think that pivoting markets says they did something wrong in the past, so they’re hesitant. It doesn’t say that, but only that the people have enough confidence to adapt to a new market with the same energy and intellect with which they addressed the original market.
JInfonet has great potential, but it will require a strong rethink and clarification of who they are in order to convert that to kinetic. From what I’ve seen of the product and two people, I hope they succeed.
TechTarget took previously published article about self-service BI, bundled it with some other articles and reprinted it.