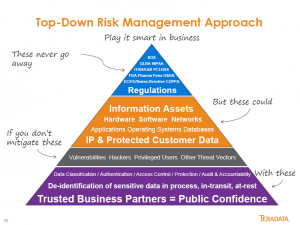
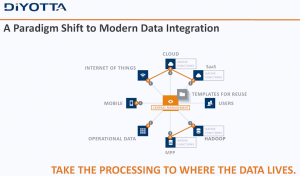
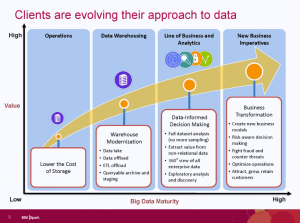
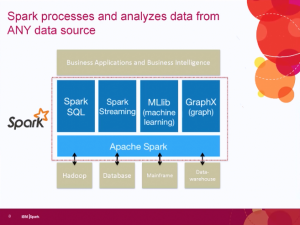
People at technology startups love to call the industry giants dinosaurs. The analogy fails for a number of reasons. The funniest is that the dinosaurs existed for many millions of years. As the large companies exist now, are the startups are saying the big companies will only disappear if we’re hit by a meteor? Companies became large by filling a need. While many might not be as nimble, their experience, especially in enterprise software, means they often see the needs of the business community while the small companies are focused too much on their “cool” technology.
This week’s Oracle webinar, hosted by the DBTA, was a good example of that. The speakers were Rich Clayton, VP Business Analytics Product Group, and Omri Traub, VP Software Development, and the subject was, no surprise, Oracle Big Data Cloud Service (OBDC. Yeah, I know. Too close to ODBC…). Before we get into the details, people need to be aware that Oracle is fully committed to the cloud, as pointed out in a recent advertorial in Forbes. Oracle is clearly competing with Amazon for enterprise cloud business. Big data is only one part of that.
Rich Clayton began the presentation by pointing towards Thomas Edison’s laboratory as an example of using the ideas from many people to not only invent things but also to figure out how to market those inventions. He brought that directly into the evolution of corporate data labs. The biggest problem, Rich stated, is that that labs are usually only populated by very technical people while they require a broader array of talents. That requirement is one of the data labs principles he defined and one I’ve also described as the missing component of many corporate data labs.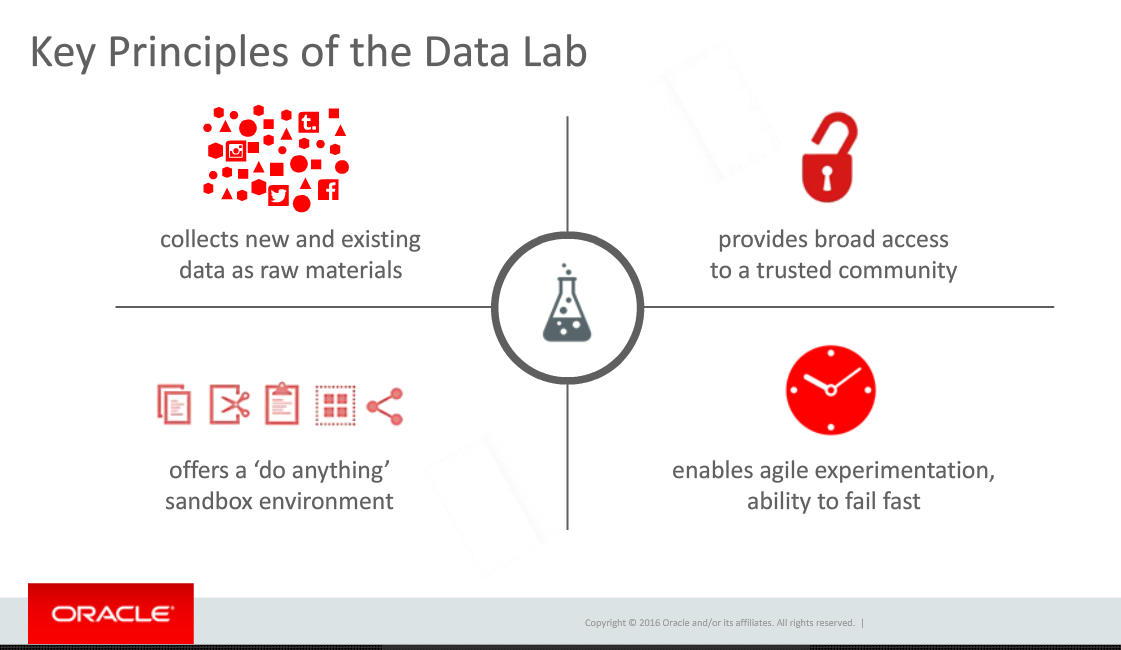
A related problem is that most products are so complex and silo’d that very technical people are needed. At this stage in business intelligence and big data, that’s the horse that needs to be addressed before the broad access cart can move.
Omri Traub then took over for the demonstration portion of the presentation. Unfortunately, he unintentionally proved the point about technical folks missing business needs by the setup he used for the demonstration. The demo was built around an enormous amount of information on New York City taxi information. While manipulating a billion record data set is cool and powerful, he never presented a business message. He pointed to the large volume of data, talked about other data sources he combined, and then played with the data to show correlations.
The problem? Omri, claimed we were gaining insight. Correlations aren’t insight. Understanding how those correlations might impact your business and ideas how to adapt business to meet what you find is insight. Nothing in the demonstration pointed towards insight.
Fortunately, Rich Clayton earlier had given a couple of case studies showing business insight gained by OBDC early customers. It would have been much better if Mr. Traub had focused on one of those cases or something similar.
The best point of the demonstration was when Omri showed how, in the middle of playing with some relationships, he easily incorporated some analysis created by a different person. As mentioned above, collaboration is critical and it looks like Oracle hasn’t limited that to just a marketing message but has worked to make sure that Oracle’s product helps the team. As many companies claim to do that and it was only an overview, your mileage might vary. Make sure when you talk to them to follow through and see whether the collaboration (not to mention the entire product…) meets your needs.
The final section was the Q&A. I’m a marketing person, so I have to be honest and state that it sounded like canned questions they wanted to address, as there was way too much about the full Oracle ecosystem brought into discussion at this point compared to what I’d expect from customers. Still, there was one important point.
A question was asked about what advanced analytics might be added. Mr. Taub had the perfect response. After quickly mentioning that, yes, Oracle was always looking at advanced analytics and how to add them, he made a much more important point. Collobaration is key and OBDC is designed to get business people involved. All analytics need to be added in a usable manner, in a way that is understandable and can be leveraged by more people than just the technical resources.
That is the critical viewpoint that a large, enterprise focused company can bring to BI, the cloud and big data. That’s why it’s foolish to write off the large companies, the ones with expertise in not just technology, but in business and business relationships. They might not move as fast, but they can move to the right places with the right products and the right business messages.