Today’s TDWI presentation (And they’ve crammed a number of webinars into this week) was led by Philip Russom, TDWI Research Director, and sponsored by Teradata. While the name of the topic was clearly a push to market their best practices report series, I have to say that this presentation was about both higher and lower level concepts than best practices, not that that’s a bad thing.
The one clear thing was the point made by Philip at the beginning. Given the title, this was a presentation aimed clearly at IT and data management issues. Considering my comments on Teradata’s presentation to the BBBT and about previous TDWI webinars, that’s a comfort zone for both organizations. They don’t understand business users of technology as well as they understand the people creating the infrastructure.
As usual, TDWI bases their discussions on the results of the vast number of very interesting surveys that are the basis of their research. The first set of numbers of interest today was the response to a question on what technical issues are pushing change. The need for analytics edged out data volumes for the top spot. That’s the one clear indication that business users are driving IT spending and should be focused on a bit more closely.
One key point made by Mr. Russom was that one of the key questions asked by knowledge workers to IT is always “Where did this data come from?” Data governance matters, even during the rush to focus on rapid analytics. He came back to the point multiple times in the presentation and it’s important for more people in IT to realize that the techniques and technologies falling in the weird category of Big Data won’t become mainstream until data governance is competently addressed by vendors.
A Sidebar on Reports v Analytics
One problem I have with the presentation, and with many of the folks discussing the new types of analytics is they create an artificial wall between reports and analytics. Philip gave an example of fraud protection and how reports would cleanse the data, hiding both the positive and negative connotations of outliers. Well, not quite. Those of us who were programmers years ago, not academics or analysts, clearly remember that exception reporting was always critical.
New analytics techniques allow us to better manipulate the same data in more complex ways or larger data sets faster, but the goal of reporting and analysis is the same: To display information in a fashion that allows actions to be derived from useful information. For some information, a simple report is appropriate, in another a Paretto diagram might be better, but they’re both valuable and there’s nothing new about the intent of modern analytics.
True best practices looks at what’s the appropriate technique for delivering each type of information. Mr. Russom did, a few slides later, talk about older and newer techniques working together as in two decks of cards being shuffled together and I think that imagery is better than his words since the decks look a lot alike.
Back to the Presentation
Another thread that ran through Philip Russom’s presentation was the mention of broader data sources. This is a key point of mine that I’m figuring out how to better document and publish, but I’m not the only one. I’ve always had a problem with the phrase “Big Data.” Big is always relative and constantly changing, plus it’s more of a hardware issue. What’s new about current data management is that the number of sources are much more varied, unstructured data is taking a more prominent role, and IT must look at how best to access very heterogeneous sources and providing integration between them. A Russom points out, IT must be focused on breadth even more than volume.
That led to his final topic, and the perfect lead-in for Teradata, that Hadoop isn’t about to replace EDW’s but that IT needs to figure out how to ensure both co-exist and lend their strengths to cover each other’s weaknesses.
Chris Twogood then took over, focused on technology issues around Hadoop, JSON and other newer tools for managing data. Being a business person, I found the most interesting thing in Chris’ presentation to be a fly-by slide on the way to technology. Teradata defines the goal of data driven business as to “Achieve sustainable competitive advantage by leveraging insights from data to deliver greater value to their customers.” The only thing I’d do is shorten it, ending at “value.” After all, the customers aren’t the only stakeholders in a business. Better insight means better financial performance that can benefit owners and employees alike.
The presentation quickly moved along to Chris discuss the breadth of data means Teradata is working to provide access to all those sources. Teradata QueryGrid™ is their solution to provide an interface across data sources. Though I’m sure they’ll hate me for saying it, think of the product as ODBC on steroids.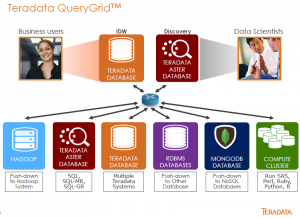
From discussing that, Mr. Twogood then made a transition to making a claim that somehow the solution means they’re creating the “disruptive data warehouse.” I know that so many people in leading edge fields want to think they’re invention something glorious and new, but it just isn’t. This is an evolutionary change and not even a big one at that. What Teradata describes as disruptive is just the same concept as defined by the federated data warehouse concept discussed since the 1990s. Technology is finally advancing to be able to provide the actuality impossible to provide back then, but it’s just normal growth. That doesn’t make it any less powerful.
To emphasize that, one question during Q&A gave Philip Russom a great opportunity reinforce a few points by referring again, to data governance. He pointed out that the issues of data governance are the same for the EDW and Big Data. He also extended that by saying that good data management means you’re always trolling for new data sources. Big data isn’t the end, it’s just a part of the continuum and where we are now.