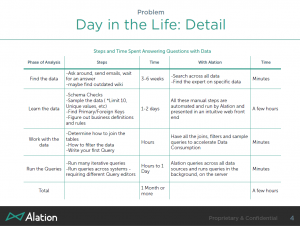
I just saw an amusing presentation by SAS. Amusing because you rarely get two presenters who are both as good at presenting and as knowledgeable about their products. We heard from Mike Frost, Senior Product Manager for Data Management, and Wayne Thompson, Chief Data Scientist. They enjoy what they do and it was contagious.
It was also interesting from the perspective of time. Too many younger folks think if a firm has been around for more than five years, it’s a dinosaur. That’s usually a mistake, but the view lives on. SAS was founded almost 40 years ago, in 1976, and has always focused on analytics. They have been historically aimed at a market that is made up of serious mathematicians doing heavy statistical work. They’re very good at what they do.
The business analysis sector has been focused on less technical, higher level business number crunching and data visualization. In the last decade, computing power has meant firms can dig deeper and can start to provide analysis SAS has been doing for decades. The question is whether or not SAS can rise to the challenge. It’s still early, but the answer seems to be a qualified but strong “yes!”
Both for good and bad, SAS is the largest privately held software company, still driven by founder James Goodnight. That means a good thing in that technically focused folks plow 23% of their revenue into R&D. However, it also leaves a question mark. I’ve worked for other firms long run by founders, one a 25+ year old firm still run by brothers. The best way to refer to the risk is that of a famous public failure: Xerox and the PC. For those who might not understand what I’m saying, read “Fumbling the Future” by Smith and Alexander. The risk comes down to the people in charge knowing the company needs to change but being emotionally wedded to what’s worked for so long.
The presentation to the BBBT shows that, while it’s still early in the change, SAS seems to be mostly avoiding that risk. They’re moving towards a clean, easier to use UI and taking their first steps towards collaboration. More work needs to be done on both fronts, but Mike and Wayne were very open and honest about their understanding the need and SAS continuing to move forward.
One of the key points by Mike Frost is one I’ve also discussed. While they disagree with me and think the data scientist does exist, the SAS message is clear that he doesn’t work in a void. The statistician, the business analyst and business management must all work in concert to match technical solutions to real business information needs.
LASR, VAE and a cast of thousands
The focus of the presentation was on SAS LASR, their in-memory analytics server. While it leverages Hadoop, it doesn’t use MapReduce because that involves disk access during processing, losing the speed advantage of in-memory applications.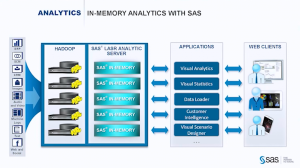
As Mike Frost pointed out, “It doesn’t do any good to run the right model too late.”
One point that still shows the need to think more about business, is that TCO was mentioned in passing. No slide or strong message supported the message. They’re still a bit too focused on technology, not what sells the business decision makers on business intelligence (BI).
Another issue was the large number of ancillary products in the suite, including Visual Data Explorer, Data Loader and others. The team mentioned that SAS is slowly moving through the products to give them the same interface, but I also hope they’re looking at integrating as much as possible so the users don’t have the annoyance of constantly moving between products.
One nice part of the demo was an example of discussing what SAS has termed “poorly structured data” as opposed to “unstructured data” that’s the rage in Hadoop. I prefer “loosely structured data.” Mike and Wayne showed the ability to parse the incoming file and have machine intelligence make an initial pass at suggesting fields. While this isn’t new, I worked at a company in 2000 that was doing that, it’s a key part of quickly integrating such data into the business environment. The company I reference had another founder who became involved in other things and it died. While I’m surprised it took firms so long to latch onto and use the technology, it doesn’t surprise me that SAS is one of the first to openly push this.
Another advantage brought by an older, global firm, related to the parsing is that it works in multiple languages, including right-to-left languages such as Hebrew and Arabic. Most startups focus on their own national language and it can be a while before the applications are truly global. SAS already knows the importance and supports the need.
Great, But Not Yet End-To-End
The only big marketing mistake I heard was towards the end. While Frost and Thompson are rightfully proud of their products, Wayne Thompson crowed that “We’re not XXX,” a reference to a major BI player, “We’re end-to-end.” However, they’d showed only minimal visualization choices and their collaboration, admittedly isn’t there.
Even worse for the message, only a few minutes later, based on a question, one of the presenters shows how you export predicted values so that visualization tools with more power can help display the information to business management.
I have yet to see a real end-to-end tool and there’s no reason for SAS to push this iteration as more than it is. It’s great, but it’s not yet a complete solution.
Summary
SAS is making a strong push into the front end of analytics and business intelligence. They are busy wrapping tools around their statistical engines that will allow them to move much more strongly out of academics and the very technical depths of life sciences, manufacturing, defense and other industries to challenge in the realm of BI.
They’re headed in the right direction, but the risk mentioned at the start remains. Will they keep focused on this growing market and the changes it requires, or will that large R&D expenditure focus on the existing strengths and make the BI transition too slow? I’m seeing all the right signs, they just need to stay on track.