Clearstory Data presented to the BBBT last week. The company is presenting itself as an end-to-end BI company, providing data access through display. Their core is what they call Data Harmonization, or trying to better merge multiple data stores into a current whole.
Data Harmonization
The presentation started with Andrew Yeung, Director of Product Marketing, giving the overview slides. The company was founded by some folks from Aster Data and has about sixty people and its mission is to “Converge more data sources faster and enable frontline business users to do collaborative data exploration to ‘answer new questions.’” A key fact Andrew brought up was that 74% of business users need to access four or more data sources (from their own research). As I’ve mentioned before, the issue is more wide data than big data, and this company understands that.
If that sounds to you like ETL, you’ve got it. Everyone thinks they have to invent new terms and ETL is such an old one and has negative connotations, so they’re trying to rebrand. There’s nothing wrong with ETL, even if you rationalize its ELT or harmonization, it’s still important and the team has a good message.
The key differentiator is that they’re adding some fundamental data and metadata to improve the blending of the data sources. That will help lower the amount of IT involvement in creating the links and the resulting data store. Mr. Yeung talked about how the application inferred relationships between field based on both data and metadata to both link data sources and infer dimensions around the key data.
Andrew ended his segment with a couple of customer stories. I’ll point out that they were anonymous, always something in my book. When a firm trusts enough to let you use its name, you have a certain level of confidence. The two studies were a CPG company and a grocery chain, good indications of ClearStory’s ability to handle large data volumes.
Architecture
The presentation was then taken over by Kumar Srivastava, Senior Director of Product Management, for the architecture discussion.
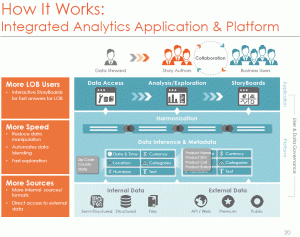
ClearStory is a cloud service provider, with access to corporate systems but work is done on their servers. Mr. Srivastava started by stating that the harmonization level and higher are run in-memory on Apache Spark.
That led to the immediate question of security. Kumar gave all the right assurances on basic network security and was also quick to transition to, not hide, the additional security and compliance issues that might prevent some data from being moved from inside the firewall to the cloud. He also said the company suggests clients mask critical information but ClearStory doesn’t yet provide the service. He admitted they’re a young firm and still working out those issues with their early customer. That’s a perfectly reasonable answer and if you talk with the company, be sure to discuss your compliance needs and their progress.
Mr. Srivastava also made a big deal about collaborative analytics, but it’s something everyone’s working on, he said nothing really new and the demo didn’t show it. I think collaboration is now a checklist item, folks want to know a firm has it, but aren’t sure how to use it. There’s time to grow.
The last issue discussed by Kumar was storyboards, the latest buzzword in the industry. He talked about them being different then dashboards and then showed a slide that makes them look like dashboards. During the demo, they show as more dynamic dashboards, with more flexible drilldown and easy capture of new dashboard elements. It’s very important but the storyboard paradigm is seriously overblown.
Demo
The final presenter was Scott Anderson, Sales Engineer, for the demonstration. He started by showing they don’t have a local client but just use a browser. Everyone’s moving to HTML5 so it’s another checklist item.
While much of the demo flew by far too quickly to really see how good the interface was, there was one clear positive element – though some analysts will disagree. Based on the data, ClearStory chooses an initial virtualization. The customer can change that on the fly, but there’s no need to decide at the very front what you need the data to be. Some analysts and companies claim that is bad, that you can send the user in the wrong direction. That’s why some firms still make the user select an initial virtualization. That, to me, is wrong. Quickly getting a visualization up helps the business worker begin to immediately understand the data then fine tune what is needed.
At the end of the presentation, two issues were discussed that had important relevance to the in-memory method of working with data: They’re not good with changing data. If you pull in data and display results, then new data is loaded over it, the results change with no history or provenance for the data. This is something they’ll clearly have to work on to become more robust.
The other issue is the question of usability. They claim this is for end users, but the demo only showed Scott grabbing a spreadsheet off of his own computer. When you start a presentation talking about the number of data sources needed for most analysis, you need to show how the data is accessed. The odds are, this is a tool that requires IT and business analysts for more than the simplest information. That said, the company is young, as are many in the space.
Summary
ClearStory is a young company working to provide better access and blending of disparate data sources. Their focus is definitely on the challenge of accessing and merging data. Their virtualizations are good but they also work with pure BI virtualization tools on top of their harmonization. There was nothing that wowed me but also nothing that came out as a huge concern. It was a generic presentation that didn’t show much, gave some promise but left a number of questions.
They are a startup that knows the right things to say, but it’s most likely going to be bleeding edge companies who experiment with them in the short term. If they can provide what they claim, they’ll eventually get some names references and start moving towards the main market.
As they move forward, I hope to see more.