Two TDWI webinars in one week? Both sponsored by SAP? Today’s was on IoT impacting data warehousing, and I was curious about how an organization that began focused on data warehousing would cover this. It ended up being a very basic introduction to IoT for data warehousing. That’s not bad. In fact. it’s good. While I often want deeper dives than presenters give, there’s certainly a place for helping people focused on one arena, in this case it’s data warehousing, get an idea of how another area, IoT, could begin to impact their world.
The problem I had was how Philip Russom, Senior Research Director for Data Management, TDWI, did that. I felt he missed out on covering some key points. The best part is that, unlike Tuesday’s machine learning webinar, SAP’s Rob Waywell, Director Hana Project Management, did a better job of bringing in case studies and discussing things more focused on the TDWI audience.
Quick soap box: Too many companies don’t understand product marketing so they under utilize their product marketers (full disclosure: I was one). I strongly feel that companies leveraging product marketing rather than product management in presentations will be more able to address business concerns rather than being focused on the products. Now, back to our regular programming…
One of the most interesting takeaways from the webinar was a poll on what level of involvement the audience has with IoT. Fifty percent of the responders said they’re not collecting IoT data and have no plans to do so. Enterprise data warehouses (EDW) are focused on high level, aggregated data. While the EDW community has been moving to blend more real time data, it tends to be other departments who are early into the IoT world. I’m not surprised by the results, nor am I worried. The expansion of IoT will bring it in to overlap EDW’s soon enough, and I’d suggest that that half of the audience is aware things will be changing and they have the foresight to begin to pay attention to it.
IoT Basics for EDW Professionals
Mr. Russom’s basic presentation was good, and folks who have only heard about IoT would do well to listen to it. However, they should be aware of a few issues.
Philip said that “the tendency is to push analytics out to the devices.” Not wholly true, and the reason is critical. A massive amount of data is being generated by what are called “edge devices.” Those are the cars, refrigerators, manufacturing robots and other devices that stream information to the core servers. IoT data is expected to far exceed the web and social media data often referred to as big data. That means that an efficient use of the internet means that edge analytics are needed to aggregate some information to minimize traffic flow.
Take, for instance, product data. As Rob Waywell mentioned, many devices create lots of standard data for which there is no problems. The system really only cares about exceptions. Therefore, an edge device might use analytics to aggregate statistics about the standard occurrences while immediately passing exceptions on to be handled in real-time.
There is also the information needed for routing. Servers in the core systems need to understand the data and its importance. The EDW is part of a full data infrastructure. the ODS (or data lake as folks are now calling it) can be the direct target of most data, while exceptions could be immediately routed to other systems. Whether it’s the EDW, ODS, or other system, most of the analysis will continue in core systems, but edge analytics are needed.
SAP Case Studies
Rob Waywell, as mentioned above, had the most important point of the presentation when he mentioned that IoT traffic is primarily about the exceptions. He had a couple of quick case studies to talk about that, and his first was great because it both showed IoT and it wasn’t about cars – the most used example. The problem is that he didn’t tie it well into the message of EDWS.
The case was about industrial worker safety in the area of gas detection and response. He showed the different types of devices that could be involved, mentioned the multiple types of alert, and described different response paths.
He then mentioned, with what I felt wasn’t enough emphasis (refer to my soap box paragraph above), the real power that a company such as SAP brings to the dance that many tinier companies can’t. In an almost throwaway comment, Mr. Waywell mentioned that SAP Hana, after managing the hazardous materials release instance, can then communicate to other SAP systems to create the official regulatory reports.
Think about that. While it doesn’t directly impact the EDW, that’s a core part of integrated business systems. That is a perfect example of how the world of IoT is going to do more than manage the basics of devices but also be used to handle the full process for with MIS is designed.
Classifications of IoT
I’ll finish up with a focus that came up in a question during Q&A. Philip Russom had mentioned an initial classification of IoT between industrial and consumer applications. That misses a whole lot of areas, including supply chain, logistics, R&D feedback, service monitoring and more. To lump all of that into “manufacturing” is to do them a disservice. The manufacturing term should be limited to the actual manufacturing process.
Rob Staywell then went a different direction. He seemed to imply the purpose of IoT was solely to handle event-driven, real-time, actions. Coming from a product manager for Hana, that’s either an understandable mistake or he didn’t clearly present his view.
There is a difference between IoT data to be operationalized and that to be analyzed. He might have just been focusing on the operational aspects, those that need to create immediate actions, without minimizing the analytical portion, but it wasn’t clear.
Summary
This was a webinar that is good for those in the data warehousing and core MIS functions who want to get a quick introduction to what IoT is and what might be coming down the pike that could impact their work. For anyone who already has a good idea of what’s coming and wants more specifics, this isn’t needed.

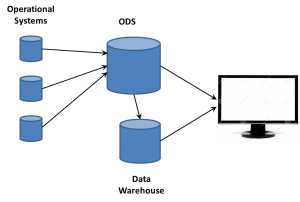
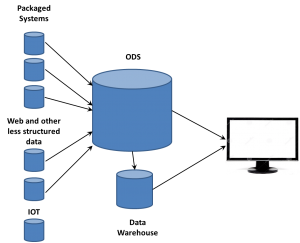 want to take ownership of concepts, especially those on the edge. So the folks working with these new data sources began talking about Big Data as somehow completely different than what came before. If that was the case, they needed to think of some term for the database where they dumped all the data extracted from web sites. Data Lakes became one term. We’ve heard data swamp and other attempts to create unique terms so a company can differentiate itself from others. However, there’s already a name.
want to take ownership of concepts, especially those on the edge. So the folks working with these new data sources began talking about Big Data as somehow completely different than what came before. If that was the case, they needed to think of some term for the database where they dumped all the data extracted from web sites. Data Lakes became one term. We’ve heard data swamp and other attempts to create unique terms so a company can differentiate itself from others. However, there’s already a name.