It’s been a while since I watched a webinar, but since business intelligence (BI) and (AI) are overlapping areas of interest, I watched Tuesday’s TDWI webinar on Machine Learning (ML). As the definition of machine learning expands out of the pure AI because of BI’s advanced analytics, it’s interesting to see where people are going with the subject.
The host was Fern Halper, VP Research, at TDWI. The guests were:
- Mike Gualtieri, VP, Forrester,
- Askhok Swaminathan, Senior Director, Product Management, SAP,
- Chandran Saravana, Senior Director, Advanced Analytics, SAP.
Ms. Halper began with a short presentation including her definition of ML as “Enabling computers to learn patterns with minimal human intervention.” It’s a bit different than the last time I reviewed one of her webinars, but that’s ok because my definition is also evolving. I’ve decided to use my own definition, “Technology that can investigate data in an environment of uncertainty and make decisions or provide predictions that inform the actions of the machine or people in that environment.” Note that I differ from my past, purist, view, of the machine learning and adjusting algorithms. I’ve done so because we have to adapt to the market. As BI analytics have advanced to provide great insight in data discovery, predictive analytics and more, many areas of BI and the purist area of learning have overlapped. Learning patterns can happen through pure statistical analysis and through self-adaptive algorithms in AI based machines.
The most interesting part of Fern Halper’s segment was a great chart showing the results of a survey asking about the importance of different business drivers behind ML initiatives. What makes the chart interesting, as you can see, is that it splits results between those groups investigating ML and those who are actively using it.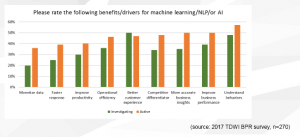
What her research shows is that while the highest segments for the active categories are customer related, once companies have seen the benefits of ML, the advantages of it for almost all the other areas jump significantly over views held during the investigation phase.
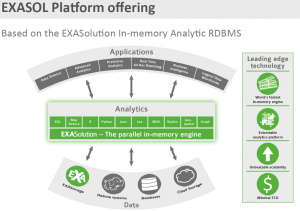
A panel discussion then proceeded, with Ms. Halper asking what sounded like pre-discussed questions (especially considering the included and relevant slides) to the three panelists. The statements by the two SAP folks weren’t bad, they were just very standard and lacked any strong differentiators. SAP is clearly building an architecture to leverage ML using their environment, but there weren’t case studies and I felt the integration between the SAP pieces didn’t bubble up to the business level.
The reason to listen to this segment is Mr. Gualtieri. He was very clear and focused on his message. While I quibble with some of the things he said about data scientists, that soap box isn’t for here. He gave a nice overview of the evolving state of ML for enterprise. The most important part of that might have been missed by folks, so I’ll bring it up here.
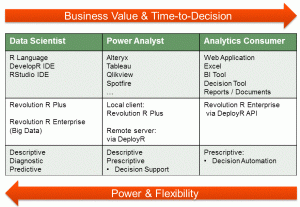
Yes, TensorFlow, R, Python and other tools provide frameworks for machine learning implementations, but they’re still at a very technical level. They aren’t for business analysts and management. He mentioned that the next generation of tools are starting to arrive, one that, just like the advent of BI, will allow people with less technical experience to more quickly use models in and gain insights from machine learning.
That’s how new technology grows, and I’d like to see TDWI focus on some of the new tools.
Summary
This was a good webinar, worth the time for those of you who are interested in a basic discussion of where machine learning is within the enterprise landscape.