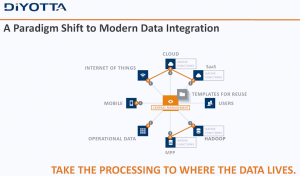
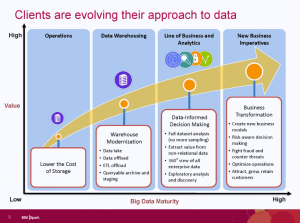
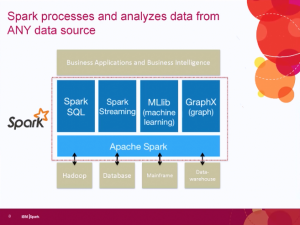
I’ve seen a few company webinars recently. As I have serious problems with their marketing, but don’t wish that to imply a problem with technology, this post will discuss the issues while leaving the companies anonymous.
What matters is letting business decision makers separate the hype from what they really need to look at when investigating products. I’m in marketing and would never deny its importance, but there’s a fine line between good marketing and misrepresentation, and that line is both subjective and fuzzy.
As the title suggests, I’ll discuss the line by describing my views of two buzzwords in business intelligence (BI). The first has been used for years, and I’ve talked about it before, it’s the concept of self-service BI. The second is the fairly new and rapidly increasing use of the word “machine” in marketing
Self-Service Still Isn’t
As I discussed in more detail in a TechTarget article, BI vendors regularly claim self-service when software isn’t. While advances in technology and user interface design are rapidly approaching full self-service for business analysts, the term is usually directed at business users. That’s just not true.
I’ve seen a couple of recent presentations that have that message strewn throughout the webinars, but the demonstrations show anything but that capability. The linking of data still requires more expertise that the typical business user needs. Even worse, some vendors limit things further. The analysts still create basic reports and templates, within which business people can wander with a bit of freedom. Though self-service is claimed, I don’t consider that to approach self-service.
The result is that some companies provide a limited self-service within the specified data set, a self-service that strongly limits discovery.
As mentioned, that self-service is either misunderstood or over promised doesn’t obviate that the technology still allows customers to gain far more insight than they could even five years ago. The key is to take the promises with a grain of salt.
When you see it, ignore the phrase “self-service.”
Prospective BI buyers need to focus on whether or not the current state of the art presents enough advantages over existing corporate methodologies to provide proper ROI. That means you should evaluate vendors based on specific improvements on your existing analytics and the products should be rigorously tested against your own needs and your team’s expertise.
Machine
Machine learning, to be discussed shortly, has exploded in usage throughout the software industry. What I recently saw, from one BI vendor, was a fun little marketing ploy to leverage that without lying. That combination is the heart of marketing and, IMO, differs from the nonsense about self-service.
Throughout the webinar, the presenter referred to the platform as “the machine.” Well, true. Babbage’s machines were analytic engines, the precursors to our computers, so complex software can reasonable be viewed as a machine. The usage brings to mind the concept of machine learning while clearly claiming it’s not.
That’s the difference, self-service states something the products aren’t while machine might vaguely bring to mind machine learning but does not directly imply that. I am both amused and impressed by that usage. Bravo!
Machine Learning and Natural Language Processing
This phrase needs a larger article, one I’m working on, but I would be remiss to not mention it here. The two previous sections do imply how machine learning could solve the self-service problem.
First, what’s machine learning? No, it’s not complex analytics. Expert systems (ES) are a segment of artificial intelligence focused on machines which can learn new things. Current analytics can use very complex algorithms, but they just drive user insight rather than provide their own.
Machine learning is the ability for the program to learn new things and to even add code that changes algorithms and data as it learns. A question to an expert system has one answer the first time, and a different answer as it learns from the mistakes in the first response.
Natural Language Processing (NLP) is more obvious. It’s the evolving understanding of how we speak, type and communicate using language. The advances have meant an improved ability for software to responds to people without clicking on lots of parameters to set search. The goal is to allow people to type or speak queries and for the ES to then respond with information at the business level.
The hope I have is that the blend will allow IT to set up systems that can learn the data structures in a company and basic queries that might be asked. That will then allow business users to ask questions in a non-technical manner and receive information in return.
Today, business analysts have to directly set up dashboards, templates and other tools that are directly used by business, often requiring too much technical knowledge. When a business person has a new idea, it has to go back to a slow cycle where the analyst has to hook in more data, at new templates and more.
When the business analyst can focus on teaching the ES where data is, what data is and the basics of business analysis, the ES can focus on providing a more adaptable and non-technical interface to the business community.
Machine learning, i.e. expert systems, and NLP are what will lead to truly self-service business applications. They’re not here yet, but they are on the horizon.