IBM at BBBT
A recent presentation by IBM at the BBBT was interesting. As usual, it was more interesting to me for the business information than the details. As unusual, they did a great job in a balanced presentation covering both. While many presentations lean too heavily in one direction or the other, this one covered both sides very well.
The main presenter was Harriet Fryman, VP of Marketing, IBM Analytics Platform. Adding information during the presentation were Steven Sit, Director of Product Management, Open Source Based Analytics Systems, and Steve Beier, Program Director, Spark Technology Center.
The focus of the talk was IBM’s commitment to Apache Spark. Before diving deep into the support, Ms. Fryman began by talking about business’ evolving data needs. Her key point is that “we all do data hording,” that modern technologies are allowing us to horde far more data than ever before, and that better ways are needed to get value out of the data.
She then proceeded to define three key aspects of the growth in analytics:
- Applying analytics in more parts of business.
- Understand the time value of data.
- The growth of machine learning and cognitive systems.
The second two overlap, as the ability to analyze large volumes of data in near real-time means a need to have systems do more analysis. The following slide also added to IBM’s picture of the changing focus on higher level information and analytics.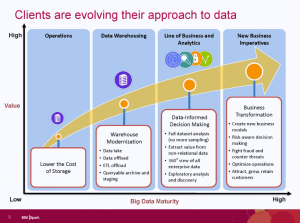
The presentation did go off on a tangent as some analysts overthought the differences in the different IBM groups for analytics and for Watson. Harriet showed great patience in saying they overlap, different people start with different things and internal organizational structures don’t impact IBM’s ability to leverage both.
The focus then turned back to Spark, which IBM sees as the unifying layer for data access. One key issue related to that is the Spark v Hadoop debate. Some people seem to think that Spark will replace Hadoop, but the IBM team expressed clear disagreement. Spark is access while Hadoop is one data structure. While Hadoop can allow for direct batch processing of large jobs, using Spark on top of Hadoop allows much more real time processing of the information that Hadoop appropriately contains.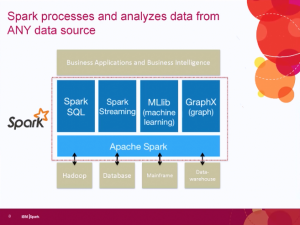
One thing on the slide that wasn’t mentioned but links up with messages from other firms, messages which I’ve supported, is that one key component, in the upper left hand corner of the slide, is Spark SQL. Early Hadoop players were talking about no-SQL, but people are continuing to accept that SQL isn’t going anywhere.
Well, most people. At least fifteen minutes after this slide was presented, an attending analyst asked about why IBM’s description of Spark seemed to be similar to the way they talk about SQL. All three IBM’ers quickly popped up with the clear fact that the same concepts drive both.
While the team continued to discuss Spark as a key business imitative, Claudia Imhoff asked a key question on the minds of anyone who noticed huge IBM going to open source: What’s in it for them? Harriet Fryman responded that IBM sees the future of Spark and to leverage it properly for its own business it needed to be part of the community, hence moving SystemML to open source. Spark may be open source, but the breadth and skills of IBM mean that value added applications can be layered on top of it to continue the revenue stream.
Much more detail was then stated and demonstrated about Spark, but I’ll leave that to the more technical analysts and vendor who can help you.
One final note put here so it didn’t distract from the main message or clutter the summary. Harriet, please. You’re a great expert and a top marketing person. However, when you say “premise” instead of “premises,” as you did multiple times, it distracts greatly from making a clear marking message about the cloud.
Summary
IBM sees the future of data access to be Apache Spark. Its analytics group is making strides to open not only align with open source, but to be an involved player to help the evolution of Spark’s data access. To ignore IBM’s combined strength in understanding enterprise business, software and services is to not understand that it is a major player in some of the key big data changes happening today. The IBM Spark initiative isn’t a marketing ploy, it’s real. The presentation showed a combination of clear business thought and strategy alongside strong technical implementation.