I’m still catching up and reviewed a video of last month’s Diyotta presentation to the BBBT. The company is another young, founded in 2011, data integration company working to take advantage of current technologies to provide not just better data integration but also better change management of modern data infrastructures. In many ways, they’re similar to another company, WhereScape, which I discussed last year. Both are young and small, while the market is large and the need is great.
The presentation was given by Sanjay Vyas, CEO, and John Santaferraro, CMO. The introduction by Sanjay was one of the best from a small company founder that I’ve seen in a long time. He gave a brief overview of the company, its size, it’s global structure (with HQ in Charlotte, NC, and two offshore development centers). Then he went straight to what most small companies leave for last: He presented a case study.
My biggest B2B marketing point is that you need to let the market know you understand it. Far too many technical founders spend their time talking about the technology they built to solve a business problem, not the business problem that was addressed by technology. Mr. Vyas went to the heart of the matter. He showed the pain in a company, the solution and, most importantly, the benefits. That is what succeeds in business.
It also wasn’t an anonymous reference, it was Scotiabank, a leading Canadian bank with a global presence. When a company that large gives a named reference to a startup as small as is Diyotta, you know the firm is happy.
John Santaferraro then took over for a bit with mostly positive impact. While he began by claiming a young product was mature because it’s version 3.5, no four year old firm still working on angel investments has a fully mature product. From the case study and what was demo’d later, it’s a great product but it’s clear it’s still early and needs work. There’s no need to oversell.
The three main markets John said Diyotta aims at are:
- Big data analytics.
- Data warehouse modernization.
- Hybrid data integration including cloud and on-premises (though John was another marketing speaker who didn’t want to use the “s” at the end).
While the other two are important, I think it’s the middle one that’s the sweet spot. They focus on metadata to abstract business knowledge of sources and targets. While many IT organizations are experimenting with Hadoop and big data, getting a better understanding and improved control over the entire EDW and data infrastructure as big data is added and new mainline techniques arrive is where a lot more immediate pain exists.
Another marketing miss that could have incorporated that key point was when Mr. Santaferrero said that the old ETL methods no longer work because “having a server in the middle of it … doesn’t exist anymore.” The very next slide was as follows.
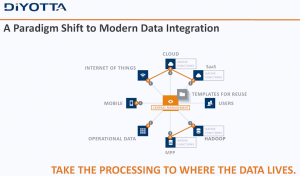
Diyotta still seems to have a server in the middle, managing the communications between sources and targets through metadata abstraction. The little “A’s” in the data extremities are agents Diyotta uses to preprocess requests locally to optimize what can be optimizes natively, but they’re still managed by a central system.
The message would be more powerful by explaining that the central server is mediating between sources and targets, using metadata, machine learning and other modern tools, to appropriately allocate processing at source, in the engine or in the target in the most optimal way.
While there’s power in the agents, that technology has been used in other aspects of software with mixed results. One concern is that it means a high need for very close partnerships with the systems in which the agents reside. While nobody attending the live presentation asked about that, it’s a risk. The reason Sanjay and John kept talking about Netezza, Oracle and Teradata is because those are the firms whose products Diyotta has created agents. Yes, open systems such as Hadoop and Spark are also covered, but agents do limit a small company’s ability to address a variety of enterprises. The company is still small, so as long as they focus on firms with similar setups to Scotiabank, they have time to grow, to add more agents and widen their access to sources; but it’s something that should be watched.
On the pricing front, they use pricing purely based on the hub. There’s no per user or per connector pricing. As someone who worked for companies that used pricing that involved connectors, I say bravo! As Mr. Vyas pointed out, their advantage is how they manage sources and targets, not which ones you want them to access. While connecting is necessary, it’s not the value add. The pricing simplifies things and can save money compared with many more complex pricing schemes that charge for parts.
The final business point concerns compliance. An analyst in the room (Sorry, I didn’t catch the name) asked about Sarbanes-Oxley. The answer was that they don’t yet directly address compliance but their metadata will make it easier. For a company that focuses on metadata and whose main reference site is a major financial institution, it would serve their business to add something to explicitly address compliance.
Summary
Diyotta is a young company addressing how enterprises can leverage big data as target and source alongside the existing infrastructure through better metadata management and data access. They are young and have many of the plusses and minuses that involves. They have some great technology but it’s early and they’re still trying to figure out how to address what market.
The one major advantage they have, given what I’ve seen in only a two hour presentation, is Sanjay Vyas. Don’t judge a startup on where they are now or where you think they need to be. Judge them on whether or not management seems capable of getting from point A to point B. Listening to Mr. Vyas, I heard a founder who understands both business and technology and will drive them in the direction they need to go.