Dataversity hosted a webinar by Matt Allen, Product Marketing Manager at MarkLogic. Mr. Allen’s purpose was to explain to the audience the basic challenges involved in big data which can be addressed by semantic analysis. He did a good job. Too many people attempting the same spend too much time on their own product. Matt didn’t do so. Sure, when he did he had some of the same issues that many in our industry have, of over selling change; but the corporate references were minimal and the first half of the presentation was almost all basic theory and practice.
Semantics and Complexity
On a related tangent, one of the books I’m reading now is Stanley McChrystal’s “Team of Teams.” In it, he and his co-authors point to a distinction between complicated and complex. A manufacturing process can be complicated, it can have lots of steps but have a clearly delineated flow. Complex problems have many-to-many relations which aren’t set and can be very difficult to understand.
That ties clearly into the message put forward by MarkLogic. The massive amount of unstructured data is complex, with text rather than fields and which need ways of understanding potential meaning. The problems in free text are such things as:
- Different words can define the same thing.
- The same word can mean different things in different contexts.
- Depending on the person, different aspects of information are needed for the same object.
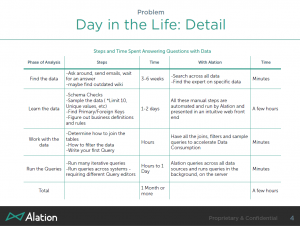
One great example that can contain all for issues was given when Matt talked about the development process. At different steps in the process, from discovery, to different development stages to product launch, there’s a lot of complexity in meanings of terms not only in development organizations but between them and all the groups in the organization with whom they have to work.
Mr. Allen then moved from discussing that complexity to talking about semantic engines. MarkLogic’s NoSQL engine has a clear market focus on semantic logic, but during this section he did well to minimize the corporate pitch and only talked about triples.
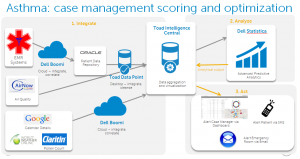
No, not baseball. Triples are a syntactical tool to link subject (person), predicate (operates), object (machine). By building those relationship, objects can be linked in a less formal and more dynamic manner. MarkLogic’s data organization is based on triples. Matt showed examples of JSON, Turtle and XML representations of triples, very neatly sliding his company’s abilities into the theory presentation – a great example of how to mention your company while giving a thought leadership presentation without being heavy handed.
Semantics, Databases and the Company
The final part of the presentation was about the database structure needed to handle semantic analytics. This is where he overlapped the theory with a stronger corporate pitch.
Without referring to a source, Mr. Allen stated that relation databases (RDBMS’) can only handle 20% of today’s data. While it’s clear that a lot of the new information is better handled in Hadoop and less structured data sources, it’s a question of performance. I’d prefer to see a focus on that.
Another error often made by folks adopting new technologies was the statement that “Relational databases aren’t solving a lot of today’s problems. That’s why people are moving to other technologies.” No, they’re extending today’s technologies with less structured databases. The RDBMS isn’t going away, as it does have its purpose. The all or nothing message creates a barrier to enterprise adoption.
The final issue is the absolutist view of companies that think they have no competitor. Mark Allen mentioned that MarkLogic is the only enterprise database using triples. That might be literally true. I’m not sure, but so what? First, triples aren’t a new concept and object oriented databases have been managing triples for decades to do semantic analysis. Second, I recently blogged about Teradata Aster and that company’s semantic analytics. While they might not use the exact same technology, they’re certainly a competitor.
Summary
Mark Allen did a very good job exposing people to why semantic analysis matters for business and then covered some of the key concepts in the arena. For folks interested in the basics to understand how the concept can help them, watch the replay or talk with folks at MarkLogic.
The only hole in the presentation is that though the high level position setting was done well, the end where MarkLogic was discussed in detail had some of the same problems I’ve seen in other smaller, still technology driven companies.
If Mr. Allen simplifies the corporate message, the necessary addition at the end of the presentation will flow better. However, that doesn’t take away from the fact that the high level overview of semantic analysis was done very well, discussing not only the concepts but also a number of real world examples from different industries to bring those concepts alive for the audience. Well done.