Last Friday’s BBBT presentation was by Michael Whitehead, CEO, WhereScape. The company seems to have a very interesting and useful product, but there’s a huge communications gap that needs to be addressed.
What They Do
One marketing issue to start was that I got most of this section from my own experience and WhereScape’s web site, not from Michael’s presentation. When someone begins a presentation by proudly announcing it is ““guaranteed there’s no corporate marketing in the presentation at all” while you’re presenting to a group of analysts, there’s a disconnect and it shows.
WhereScape has two products, Red and 3D, to help build and maintain data structures. The message is focused on data warehouses, but I’ll discuss that more in the next section. One issue was that their demonstration didn’t work as there seemed to be a problem connecting between their tablet and the BBBT display system, so much of what I’m saying is theory rather than anything demonstrated.
Red is their tool to build data warehouses. Other tools exist and have been around for decades, Informatica being just one competing firm.
3D is where the differentiation comes in. Everyone in IT understands that nightmare that is upgrading major software installations such as ERP, CRM and EDW systems. Even migrating from one version to the next of a single vendor can involve months of planning, testing and building, followed by more months of parallel runs to be safe. A better way of analyzing and modifying data structures that can compress the time frame can have a large positive impact upon a corporation. That’s what WhereScape is attempting.
What They Say
However, their message is all “Automation! Automation! Automation!” and the short part of the demo that worked showed some automated analysis but a lot of clicks necessary to accomplish the task. From what I saw, it will definitely speed up the tasks, if as advertised, with clear time and money savings, but it’s not as automated as implied and I think a better message is needed.
In addition, their message is focused on data warehouses while Michael said “We’re in the automation business not the data warehouse business,” which really doesn’t say anything.
Michael did talk for a bit about the bigger data picture that includes data warehouses as part of the full solution, but again there’s no clear message. While saying that he doesn’t like the term Data Lake, he’s another that can’t admit that it’s just the ODS. There’s also a discussion of the logical data warehouse, also not something new.
One critical and important thing Mr. Whitehead mentioned was something I’ve heard from a few people recently, the point that Hadoop and other “unstructured databases” aren’t really unstructured, they support late binding, the ability to not have to define a structure a priori but to get the data and then understand and define a useable structure for analysis.
What They Need to Say
This is the tough one and not something I’m going to solve in a short column. The company is targeting a sweet spot. Data access has exploded and that includes EDW’s not going away, the misnamed concept of Big Data and much more. Many products have been created to build databases to manage that data but the business intelligence industry is still in the place packaged, back-end systems were in the 1990s. Building is easier than maintaining and upgrading. A firm that can help IT manage those tasks in an efficient, affordable and accurate way will do well.
WhereScape seems to be aimed at that. However, their existing two-fold focus on automation and data warehousing is wrong. First, it doesn’t seem all that automated yet and, even if it was, automation is the tool rather than the benefit. They need to focus on the ROI that the automation presents IT. Second, from what was discussed the application has wider applicability than just EDW’s. It can address data management issues for a wider area of business intelligence sources and the message needs to include that.
Summary
Though the presentation was very disjointed, WhereScape seems to have focused on a clearly relevant and necessary niche in the market: How to better maintain and upgrade the major data sources needed to gain business understanding.
Right now, while there is a marketing staff at the company, WhereScape’s message seems to be solely coming from the co-founder and CEO. While that was ok in the very early days, they have some good customer stories, having led with Tesco’s success in this presentation, and it’s time to leverage a stronger and clearer core message to the market.
Where the issue seems to be is the problem I’ve repeatedly seen about messaging. The speed of the industry has increased and business intelligence is, on a whole, crossing Jeffrey Moore’s chasm. That means even younger firms need to transition from a startup, technically focused, message to a broader one much more rapidly than vendors needed to do so in the past.
While WhereScape has what seems to be the strong underpinnings of a successful product, they need to do some seriously brainstorming in order to clarify and incorporate a business oriented messaged throughout their communications channels – including in presentations by founders.

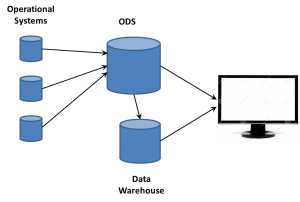
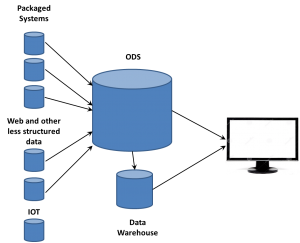 want to take ownership of concepts, especially those on the edge. So the folks working with these new data sources began talking about Big Data as somehow completely different than what came before. If that was the case, they needed to think of some term for the database where they dumped all the data extracted from web sites. Data Lakes became one term. We’ve heard data swamp and other attempts to create unique terms so a company can differentiate itself from others. However, there’s already a name.
want to take ownership of concepts, especially those on the edge. So the folks working with these new data sources began talking about Big Data as somehow completely different than what came before. If that was the case, they needed to think of some term for the database where they dumped all the data extracted from web sites. Data Lakes became one term. We’ve heard data swamp and other attempts to create unique terms so a company can differentiate itself from others. However, there’s already a name.