The latest presentation at the BBBT was by Amit Bendov, CEO, Sisense. First marketing warning: If you’re going to their web site, be prepared. Maybe it’s only for some weird Halloween thing, but the yellow and black background of the web site is the one of the ugliest thing I’ve seen for a professional company. However, let’s look under the covers, because it gets better.
The company was founded in 2004 and Amit says the first sales were in 2010. There’s a good reason for that delay. They are yet another young company who talks about being a full stack BI provider, being more than a visualization tool but also supposedly providing ETL, data storage and the full flow for your information supply chain from source systems to display. That technology took a while to develop.
Technology: Better integration of memory and Disk
The heart of their system is a patent pending technology that tightly integrates cpu cache, RAM and disk to better leverage all storage methods for higher performance. The opportunities that theory provides are enough that they’ve received $50 million (USD) in venture funding, $30 million in their latest round, earlier this year.
As they are a startup, it’s no surprise that the case studies given were for SMB or departments within enterprises. That’s the normal pattern, where a smaller group takes advantage of flexibility to try new products to solve focused problems. As their customer list includes companies such as Ebay, Wix, ESPN and Merck, companies with lots of data, those early entrants increase the potential if Sisense continues to perform.
Another key technology component is their columnar database. They created a proprietary one to be able to support their management technology. That’s completely understandable as their database isn’t purely on disk or memory, but in a combined mix that needs special database management.
The final key to their technology is that they worked to ensure the software runs on commodity chips from the X86 heritage. That means it runs on normal, affordable, off the shelf servers, not on high priced appliances.
The combination of the speed and affordability of the technology is justification for the rounds of funding they’ve received.
Really full stack?
One fuzziness that I’ve mentioned with other full stack vendors is the ETL side of the process. The growth of Cloud companies such as Salesforce, and the accessibility of their APIs, means that you can get a lot of information out of systems aimed at SMB. However, true enterprise ETL means accessing a very wide variety of systems with much less easy or open APIs. When Mr. Bendov talked about multiple systems, it seems, from presentation and demo, that he’s talking about multiple instances of simple databases or open APIs, and not a breadth of source types. There wasn’t a lot of choice in the connection section of his application.
That’s not a problem for companies at Sisense’s state of maturity, as long as there’s a business plan to expand to more enterprise sources. They need to focus on proving the technology in the short term and having more heterogeneous access in their tool bag for the future.
Another issue is the question of what, exactly, their database is. Amit Bendov made a brief comment about not needed data warehouse, but as I and others quickly brought up, there are two problems with that statement. First, they would seem to be a data warehouse. They’re extracting information from source systems, transforming that information even if not into the old star-schema structures, and providing the aggregate information for analysis. Isn’t that a high level description of a warehouse? Second, as they’re young and focused on SMB or departments, as with other companies who serve visualization, they might need to look at customer demands and get access to corporate data warehouses as another source.
The old definition of a federated data warehouse seems to be evolving into today’s environment where sometimes an EDW is a source, other times a result and sometimes it’s made up of multiple accessible components such as Sisense and other databases. Younger companies who disparage EDWs need to be careful if they wish to address the enterprise market. The EDW is evolving, not dying off.
User interface and more
One of my first trips to Israel was, in part, when my boss and I had to bring a couple of UI specialists to show Mercury Interactive’s programmers why it might be nice to rethink application interfaces. It’s wonderful what twenty years have wrought. Amit Bendov says that Sisense has one UI specialist for every two programmers, and the user interface shows that. While I mentioned that they need broader ETL access, the simplicity of getting to sources is clear. While you still will need a business analyst to understand some column names, it’s a very easy to use interface.
The same is true in the visualization portions of their application. While it’s still a simpler tool, it has all the basics and is very clear to understand and use.
Paving the way for their spread into enterprise, the Sisense team also supports single-sign on, basic data access control, both in global administration and in the user interface, and other things that will be needed to convince a larger corporation to spread the technology.
Summary
Sisense looks like a startup in a great position. Their technology is well thought out and seems to be performing very well in the early stages. Affordable, fast, business intelligence is something nobody will turn down.
The challenge is two-fold:
- Do they have the technology plans to help them address larger enterprise issues?
- Do they have the mindset to understand the importance not only in marketing, but in changing the marketing to a more business focus?
This is the same refrain you’ve heard from me before and which you’ll hear again. This is the Chasm challenge. Their technology has a great start, but their web site and presentation show they aren’t yet thinking bigger and we’ll have to see what the future holds both for the technology and the messaging.
Business intelligence is a very visible market and one growing quickly. While small companies need to focus on the early adopters, they must very rapidly learn how to address the enterprise, both in products and marketing.
High performance BI at a reasonable cost is a great sell, but Sisense isn’t yet read for full enterprise. Sisense has a great start but life is fluid.
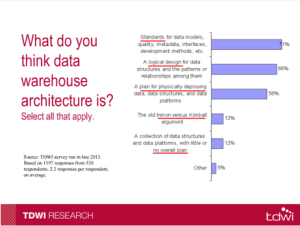 Another key point was made as to the evolving nature of the definition of data warehousing. Twenty years ago, it was about creating the repository for combining and accessing the data. That is now definition number three. The top two responses show a higher level business process and strategy in place than “just get it!”Where I have a problem with the presentation is when Mr. Russom stated that analytics are different than reporting. That’s a technical view and not a business one. His talk contained the reality that first we had to get the data, now we can move on to more in depth analysis, but he still thinks they’re very different. It’s as if there’s a wall between basic “what’s the data” and “finding out new things,” concepts he said don’t overlap. Let’s look at the current state of BI. A “report” might start with a standard layout of sales by territory. However, the Sales EVP might wish to wander the data, drilling down and slicing & dicing to understand things better by industry in territory, cities within and other metrics across territories. That combines what he defines as separate reporting and data discovery.
Another key point was made as to the evolving nature of the definition of data warehousing. Twenty years ago, it was about creating the repository for combining and accessing the data. That is now definition number three. The top two responses show a higher level business process and strategy in place than “just get it!”Where I have a problem with the presentation is when Mr. Russom stated that analytics are different than reporting. That’s a technical view and not a business one. His talk contained the reality that first we had to get the data, now we can move on to more in depth analysis, but he still thinks they’re very different. It’s as if there’s a wall between basic “what’s the data” and “finding out new things,” concepts he said don’t overlap. Let’s look at the current state of BI. A “report” might start with a standard layout of sales by territory. However, the Sales EVP might wish to wander the data, drilling down and slicing & dicing to understand things better by industry in territory, cities within and other metrics across territories. That combines what he defines as separate reporting and data discovery.