The latest BBBT presentation was from HP Vertica’s Will Cairns and Steve Sarsfield. I know it’s hard to miss HP’s presence in any market, but for those few of you who may have done so HP acquired Vertica in early 2011. Vertica is a columnar database focused on large data sources for analytics. Will and Steve were a good tag team, switching back and forth as need be; so unlike other presentation reviews I will rarely be noting who said what.
The smallest installation they mentioned runs on HP Vertica is 1.5 terabytes up to very large ones such as at Facebook, their largest customer. Without a doubt, HP plays at the larger end of the analytics market. They have a strong and powerful database and it seems HP’s hardware experience and Vertica’s database knowledge seems to have been integrated far better than other HP acquisitions in the previous decade.
The problem I often come back to discuss, whether talking about a startup or a company such as HP, is the issue of technical problems versus business solutions.
Will Cairns did say one thing that should be paid attention to by many who talk about unstructured data. His very accurate point is that “unstructured data doesn’t stay unstructured long.” We talk about conversations as unstructured, but to get information from those, we must part the syntax of sentences, look for key words and meaning, and extract semantics with meaning. Those items can then be similarly structured in order to compare, analyze and draw conclusions.
However, the weak spot in his eyes is his title. He constantly referred to “supporting data scientists” rather than supporting data science. As the programmers who know statistics create more and more packages that can analyze data, it’s the analytical capabilities being provided to business people that matters, not the people who call themselves data scientists who also just exist to serve the end business use.
One interesting techie note about their MPP database is that there isn’t an automatic lead node. While there’s no independent analysis for intelligence allocation of notes other than, it seems, basic load balancing, the idea that you can automatically define a lead node based on balancing, not before, does imply a good ability to manage distributed resources.
One thing I’ve asked a few folks who push columnar databases came up again in this presentation. They were talking about something called projections, which seemed to be ways to index the data for faster access. However, they claimed it’s not indexing but gave no clear explanation.
I then asked the question that always intrigues me. It’s clear that columnar databases have a great strength in analytics across records because indexes aren’t needed for columns, but it’s clear that both row and column based analyses have value, so getting a clearer picture how any database supports both would seem to be important. I pointed out that indexes in row-based databases exist to allow faster search of columns. The question is: What techniques are used to speed up row based searches in columnar databases if no indexes exist. They didn’t have an answer.
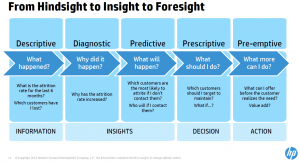
One slide that created a great conversation was one of the types of analytics and their definitions. Claudia Imhoff and others questioned the difference between predictive, prescriptive and pre-emptive analytics. While better clarity is definitely needed, the attempt is a great conversation starter for the industry.
Summary
HP Vertica seems to be a database that should be evaluated for large data volume analytics. However, they seem to have a focus on the technology not on why companies want the technology. There was no real discussion of results, or of partnerships with BI vendors to provide end user value. I expect that successful sales won’t be purely HP. They are focused purely on IT and programmers who are building very complex algorithms. They’ll need either a channel or ISV partner to round out the picture to an enterprise who needs to see the full business value chain.
It seems to be a very strong product, but only part of the solution.