Here’s an article on Forbes about Tableau buying Empirical Systems.
Short post on Tableau acquiring an MIT AI spinoff
Leave a reply
Here’s an article on Forbes about Tableau buying Empirical Systems.
My focus on business intelligence the last few years, my long term interest in artificial intelligence and the growth of machine learning came together to drive the content for my latest Forbes article.
In my work with TIRIAS Research, I’m covering machine learning. As part of that, I am publishing articles on Forbes. One thing I’ve started this month, with two articles, is a thread on management AI. The purpose is to take specific parts of AI and machine learning that are often described very technically, and present them in a way that management can understand what they are and, more importantly, why they provide value to decision making.
VentureBeat hosted a webinar that missed the mark in the title, but is still worth a watch for those interested in how technology is changing the banking industry. Artificial intelligence (AI) was only discussed a few times, but the overarching discussion of the relationship between the young financial technology (fintech) companies and the existing banking infrastructure was of great value.
The speakers were:
The opening question was about the relationship between fintech and banking organizations. The general response was that the current maturity of fintech means that most companies are focusing on one or two specific products or services, while banks are the broad spectrum organizations who will leverage that to provide the solutions to customers. Katy Gibson did point out that while Yodlee does focus on B2B, other fintech companies are trying to go B2C and we’ll have to see how that works out. Dion Lisle suggests that he sees the industry maturing for the next 18-24 months, then expects to see mergers and acquisitions start to consolidate the two types of businesses.
One of the few AI questions, one on how it will be incorporated, brought a clear response from Ms. Gibson. Just as other companies have begun to realize as machine learning and other AI applications begin to be operationalized, clean data is just as important as it always has been. She points out that banking information comes from multiple sources, isn’t clean and is noisy. Organizations are going to have to spend a lot of time and planning to ensure that the systems will be able to be fed useable information that provides accurate insight.
There was an interesting AI-adjacent question, one where I’m not sure I agree with the panelists. Imagine a consumer at home, querying Alexa, Siri, or other AI voice system and asking a financial question, one such as whether or not personal financial systems are good to buy a specific item. If the answer that comes back is wrong, who will the consumer blame?
The panelist consensus seems to be that they will blame the financial institution. I’m not so sure. Most people are direct. They blame the person (or voice system) in front of them. That’s one reason why customer support call centers have high turnover. The manufacturing system might be to blame for a product failure, but it’s the person on the other end of the line who receives the anger. The home AI companies will need to work with all the service providers, not just in fintech, to ensure not just legal agreements specify responsibility, but that also the voice response reflects the appropriate agreements.
The final item I’ll discuss was a key AI issue. The example discussed was a hypothetical where training figured out that blue eyed people default on home loans more often. What are the legal ramifications of such analysis. I think it was Dion (apologies if it was someone else), pointed out the key statistical statement about correlation not meaning causality. It’s one thing to recognize a relationship, it’s another to assume one thing causes another.
Katy Gibson went further into the AI side and pointed out that fintech requires supervised learning in the training of machine systems. It’s not just the pure correlation/causality issues that matter. Legal requirements specify anti-discrimination measures. That means that unsupervised learning is not just finding false links, it could be finding illegal ones. Supervised learning means data sets including valid and invalid results must be used to ensure the system is trained for the real world.
There were more topics discussed, including an important one about who owns privacy, but they weren’t related to AI.
It was an interested webinar with my usual complaint about large panels: There were too many people for the short time. All of these folks were interesting, but smaller groups and a more tightly focused discussion would have better served the audience.
Two TDWI webinars in one week? Both sponsored by SAP? Today’s was on IoT impacting data warehousing, and I was curious about how an organization that began focused on data warehousing would cover this. It ended up being a very basic introduction to IoT for data warehousing. That’s not bad. In fact. it’s good. While I often want deeper dives than presenters give, there’s certainly a place for helping people focused on one arena, in this case it’s data warehousing, get an idea of how another area, IoT, could begin to impact their world.
The problem I had was how Philip Russom, Senior Research Director for Data Management, TDWI, did that. I felt he missed out on covering some key points. The best part is that, unlike Tuesday’s machine learning webinar, SAP’s Rob Waywell, Director Hana Project Management, did a better job of bringing in case studies and discussing things more focused on the TDWI audience.
Quick soap box: Too many companies don’t understand product marketing so they under utilize their product marketers (full disclosure: I was one). I strongly feel that companies leveraging product marketing rather than product management in presentations will be more able to address business concerns rather than being focused on the products. Now, back to our regular programming…
One of the most interesting takeaways from the webinar was a poll on what level of involvement the audience has with IoT. Fifty percent of the responders said they’re not collecting IoT data and have no plans to do so. Enterprise data warehouses (EDW) are focused on high level, aggregated data. While the EDW community has been moving to blend more real time data, it tends to be other departments who are early into the IoT world. I’m not surprised by the results, nor am I worried. The expansion of IoT will bring it in to overlap EDW’s soon enough, and I’d suggest that that half of the audience is aware things will be changing and they have the foresight to begin to pay attention to it.
Mr. Russom’s basic presentation was good, and folks who have only heard about IoT would do well to listen to it. However, they should be aware of a few issues.
Philip said that “the tendency is to push analytics out to the devices.” Not wholly true, and the reason is critical. A massive amount of data is being generated by what are called “edge devices.” Those are the cars, refrigerators, manufacturing robots and other devices that stream information to the core servers. IoT data is expected to far exceed the web and social media data often referred to as big data. That means that an efficient use of the internet means that edge analytics are needed to aggregate some information to minimize traffic flow.
Take, for instance, product data. As Rob Waywell mentioned, many devices create lots of standard data for which there is no problems. The system really only cares about exceptions. Therefore, an edge device might use analytics to aggregate statistics about the standard occurrences while immediately passing exceptions on to be handled in real-time.
There is also the information needed for routing. Servers in the core systems need to understand the data and its importance. The EDW is part of a full data infrastructure. the ODS (or data lake as folks are now calling it) can be the direct target of most data, while exceptions could be immediately routed to other systems. Whether it’s the EDW, ODS, or other system, most of the analysis will continue in core systems, but edge analytics are needed.
Rob Waywell, as mentioned above, had the most important point of the presentation when he mentioned that IoT traffic is primarily about the exceptions. He had a couple of quick case studies to talk about that, and his first was great because it both showed IoT and it wasn’t about cars – the most used example. The problem is that he didn’t tie it well into the message of EDWS.
The case was about industrial worker safety in the area of gas detection and response. He showed the different types of devices that could be involved, mentioned the multiple types of alert, and described different response paths.
He then mentioned, with what I felt wasn’t enough emphasis (refer to my soap box paragraph above), the real power that a company such as SAP brings to the dance that many tinier companies can’t. In an almost throwaway comment, Mr. Waywell mentioned that SAP Hana, after managing the hazardous materials release instance, can then communicate to other SAP systems to create the official regulatory reports.
Think about that. While it doesn’t directly impact the EDW, that’s a core part of integrated business systems. That is a perfect example of how the world of IoT is going to do more than manage the basics of devices but also be used to handle the full process for with MIS is designed.
I’ll finish up with a focus that came up in a question during Q&A. Philip Russom had mentioned an initial classification of IoT between industrial and consumer applications. That misses a whole lot of areas, including supply chain, logistics, R&D feedback, service monitoring and more. To lump all of that into “manufacturing” is to do them a disservice. The manufacturing term should be limited to the actual manufacturing process.
Rob Staywell then went a different direction. He seemed to imply the purpose of IoT was solely to handle event-driven, real-time, actions. Coming from a product manager for Hana, that’s either an understandable mistake or he didn’t clearly present his view.
There is a difference between IoT data to be operationalized and that to be analyzed. He might have just been focusing on the operational aspects, those that need to create immediate actions, without minimizing the analytical portion, but it wasn’t clear.
This was a webinar that is good for those in the data warehousing and core MIS functions who want to get a quick introduction to what IoT is and what might be coming down the pike that could impact their work. For anyone who already has a good idea of what’s coming and wants more specifics, this isn’t needed.
It’s been a while since I watched a webinar, but since business intelligence (BI) and (AI) are overlapping areas of interest, I watched Tuesday’s TDWI webinar on Machine Learning (ML). As the definition of machine learning expands out of the pure AI because of BI’s advanced analytics, it’s interesting to see where people are going with the subject.
The host was Fern Halper, VP Research, at TDWI. The guests were:
Ms. Halper began with a short presentation including her definition of ML as “Enabling computers to learn patterns with minimal human intervention.” It’s a bit different than the last time I reviewed one of her webinars, but that’s ok because my definition is also evolving. I’ve decided to use my own definition, “Technology that can investigate data in an environment of uncertainty and make decisions or provide predictions that inform the actions of the machine or people in that environment.” Note that I differ from my past, purist, view, of the machine learning and adjusting algorithms. I’ve done so because we have to adapt to the market. As BI analytics have advanced to provide great insight in data discovery, predictive analytics and more, many areas of BI and the purist area of learning have overlapped. Learning patterns can happen through pure statistical analysis and through self-adaptive algorithms in AI based machines.
The most interesting part of Fern Halper’s segment was a great chart showing the results of a survey asking about the importance of different business drivers behind ML initiatives. What makes the chart interesting, as you can see, is that it splits results between those groups investigating ML and those who are actively using it.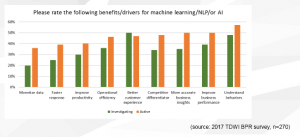
What her research shows is that while the highest segments for the active categories are customer related, once companies have seen the benefits of ML, the advantages of it for almost all the other areas jump significantly over views held during the investigation phase.
A panel discussion then proceeded, with Ms. Halper asking what sounded like pre-discussed questions (especially considering the included and relevant slides) to the three panelists. The statements by the two SAP folks weren’t bad, they were just very standard and lacked any strong differentiators. SAP is clearly building an architecture to leverage ML using their environment, but there weren’t case studies and I felt the integration between the SAP pieces didn’t bubble up to the business level.
The reason to listen to this segment is Mr. Gualtieri. He was very clear and focused on his message. While I quibble with some of the things he said about data scientists, that soap box isn’t for here. He gave a nice overview of the evolving state of ML for enterprise. The most important part of that might have been missed by folks, so I’ll bring it up here.
Yes, TensorFlow, R, Python and other tools provide frameworks for machine learning implementations, but they’re still at a very technical level. They aren’t for business analysts and management. He mentioned that the next generation of tools are starting to arrive, one that, just like the advent of BI, will allow people with less technical experience to more quickly use models in and gain insights from machine learning.
That’s how new technology grows, and I’d like to see TDWI focus on some of the new tools.
This was a good webinar, worth the time for those of you who are interested in a basic discussion of where machine learning is within the enterprise landscape.
Cloudera held a pretty impressive web event this morning. It was a mini-conference, with keynotes, some breakout tracks and even a small vendor area. The event was called Cloudera Now, and the link is the registration one. I’ll update it if they change once it’s VOD.
The primary purpose was to present Cloudera as the company for data support in the rapidly growing field of Machine Learning (ML). Given the state of the industry, I’ll say it was a success.
As someone who has an MS focused on artificial intelligence (ancient times…) and has kept up with it, there were holes, but the presentations I watched did set the picture for people who are now hearing about it as a growing topic.
The cleanest overview was a keynote presentation by Tom Davenport, Professor of IT and Management, Babson College. That’s worth registering for those who want to get a well presented overview.
Right after that, he and Amy O’Conner, Big Data Evangelist at Cloudera, had a small session that was interesting. On the amusing side, I like how people are finally beginning to admit that, as Amy mentioned, that the data scientist might not be defined as just one person. I’ll make a fun “I told you so” comment by pointing to an article I published more than three years ago: The Myth of the Data Scientist.
After the keynotes, there were three session of presentations, each with three seminars from which to choose. The three I attended were just ok, as they all dove too quickly into the product pitches. Given the higher level context of the whole event, I would have liked them all to spent more time discussing the market and concepts far longer, and then had much briefer pitch towards the end of the presentations. In addition, they seem too addicted to the word “legacy,” without some of them really knowing what that meant or even, in one case, getting it right.
However, those were minor problems given what Cloudera attempted. For those business people interested in hearing about the growing intersection between data, analytics, and machine learning, go to Cloudera’s site and take some time to check out Cloudera Now.
I’ve seen a few company webinars recently. As I have serious problems with their marketing, but don’t wish that to imply a problem with technology, this post will discuss the issues while leaving the companies anonymous.
What matters is letting business decision makers separate the hype from what they really need to look at when investigating products. I’m in marketing and would never deny its importance, but there’s a fine line between good marketing and misrepresentation, and that line is both subjective and fuzzy.
As the title suggests, I’ll discuss the line by describing my views of two buzzwords in business intelligence (BI). The first has been used for years, and I’ve talked about it before, it’s the concept of self-service BI. The second is the fairly new and rapidly increasing use of the word “machine” in marketing
As I discussed in more detail in a TechTarget article, BI vendors regularly claim self-service when software isn’t. While advances in technology and user interface design are rapidly approaching full self-service for business analysts, the term is usually directed at business users. That’s just not true.
I’ve seen a couple of recent presentations that have that message strewn throughout the webinars, but the demonstrations show anything but that capability. The linking of data still requires more expertise that the typical business user needs. Even worse, some vendors limit things further. The analysts still create basic reports and templates, within which business people can wander with a bit of freedom. Though self-service is claimed, I don’t consider that to approach self-service.
The result is that some companies provide a limited self-service within the specified data set, a self-service that strongly limits discovery.
As mentioned, that self-service is either misunderstood or over promised doesn’t obviate that the technology still allows customers to gain far more insight than they could even five years ago. The key is to take the promises with a grain of salt.
When you see it, ignore the phrase “self-service.”
Prospective BI buyers need to focus on whether or not the current state of the art presents enough advantages over existing corporate methodologies to provide proper ROI. That means you should evaluate vendors based on specific improvements on your existing analytics and the products should be rigorously tested against your own needs and your team’s expertise.
Machine learning, to be discussed shortly, has exploded in usage throughout the software industry. What I recently saw, from one BI vendor, was a fun little marketing ploy to leverage that without lying. That combination is the heart of marketing and, IMO, differs from the nonsense about self-service.
Throughout the webinar, the presenter referred to the platform as “the machine.” Well, true. Babbage’s machines were analytic engines, the precursors to our computers, so complex software can reasonable be viewed as a machine. The usage brings to mind the concept of machine learning while clearly claiming it’s not.
That’s the difference, self-service states something the products aren’t while machine might vaguely bring to mind machine learning but does not directly imply that. I am both amused and impressed by that usage. Bravo!
This phrase needs a larger article, one I’m working on, but I would be remiss to not mention it here. The two previous sections do imply how machine learning could solve the self-service problem.
First, what’s machine learning? No, it’s not complex analytics. Expert systems (ES) are a segment of artificial intelligence focused on machines which can learn new things. Current analytics can use very complex algorithms, but they just drive user insight rather than provide their own.
Machine learning is the ability for the program to learn new things and to even add code that changes algorithms and data as it learns. A question to an expert system has one answer the first time, and a different answer as it learns from the mistakes in the first response.
Natural Language Processing (NLP) is more obvious. It’s the evolving understanding of how we speak, type and communicate using language. The advances have meant an improved ability for software to responds to people without clicking on lots of parameters to set search. The goal is to allow people to type or speak queries and for the ES to then respond with information at the business level.
The hope I have is that the blend will allow IT to set up systems that can learn the data structures in a company and basic queries that might be asked. That will then allow business users to ask questions in a non-technical manner and receive information in return.
Today, business analysts have to directly set up dashboards, templates and other tools that are directly used by business, often requiring too much technical knowledge. When a business person has a new idea, it has to go back to a slow cycle where the analyst has to hook in more data, at new templates and more.
When the business analyst can focus on teaching the ES where data is, what data is and the basics of business analysis, the ES can focus on providing a more adaptable and non-technical interface to the business community.
Machine learning, i.e. expert systems, and NLP are what will lead to truly self-service business applications. They’re not here yet, but they are on the horizon.
Teradata’s recent presentation at the BBBT was very interesting. The focus, no surprise, was on Teradata Aster, but Chris Twogood, VP Products and Services Marketing, and John Thuma, Director of Aster Strategy and Analytics, took a very different approach than was taken a year earlier.
Chris Twogood started the talk with the usual business overview. Specific time was spent on four recent product announcements. The most interesting announcement was about their support for Presto, a SQL-on-Hadoop project. They are the first company to provide commercial support for the open source technology. As Chris pointed out, he counted “13 different SQL-on-Hadoop variants.” Because of the importance of SQL access and the perceived power of Presto, Teradata has committed to strengthening its presence with that offering. SQL is still the language for data access and integrating Hadoop into the rest of the information ecosystem is a necessary move for any company serving any business information market. This helps Teradata present a leadership image.
Discussion then turned to the evolution of data volumes and analytics capabilities. Mr. Twogood has a great vision of that history, but the graphic needs serious work. I won’t copy it because the slide was far too busy. The main point, however, was the link between data volumes and sources with the added capabilities to look at business in a more holistic way. It’s something many people are discussing but he seems to have a much better handle on it than most others who talk to the point, he just needs to fine tune the presentation.
As most people have seen, the much of the new data coming in under the big data rubric is customer data from sources such as the web, call logs and more. Being able to create a more unified view of the customer matters. Chris Twogood wrapped up his presentation by referring to a McKinsey & Co. survey that pointed out, among other things, that studying customer journeys can increase predictive accuracy of customer satisfaction and churn by 30-40%. Though it also points out that 56% of customer interactions are through multi-channel means, one of the key areas of focus today is the journey through a web site.
With that lead-in, John Thuma took over to talk about Aster and how it can help with on-site search. He began by stating that 25-30% of web site visitors using search leave the site if the wanted result isn’t in first three items returned, while 75% abandon if the result isn’t on first page. Therefore it’s important to have searches that understand not only the terms that the prospective customer enters but possible meanings and alternatives. John picked a very simple and clear example, depending on the part of the country, somebody might search on crock pot, slow cooker or pressure cooker but all should return the same result.
While Mr. Thuma’s presentation talked about machine learning in general, and did cover some of the other issues, the main focus of that example is Natural Language Processing (NLP). We need to understand more than the syntax of the sentence, but also improve our ability to comprehend semantic meaning. The demonstration showed some wonderful capabilities of Aster in the area of NLP to improve search capabilities.
One feature is what Teradata is calling “apps,” a term that confuses them with mobile apps, a problematic marketing decision. They are full blown applications that include powerful capabilities, applications customization and very nice analytics. Most importantly, John clearly points out that Aster is complex and that professional services are almost always required to take full advantage of the Aster capabilities. I think that “app” does a disservice to the capabilities of both Aster and Teradata.
One side bar about technical folks not really understanding business came from one analyst attending the presentation who suggested that ““In some ways it would be nice to teach the searchers what words are better than others.” No, that’s not customer service. It’s up to the company to understand which words searchers mean and to use NLP to come up with a real result.
A final nit was that the term “self-service” was used while also talking about the requirement for both professional services from Teradata and a need for a mythical data scientist. You can’t, as they claimed, used Aster to avoid the standard delays from IT for new reports when the application process is very complex. Yes, afterwards you can use some of the apps like you would a visualization tool which allows the business user to do basic investigation on her own, but that’s a very limited view of self-service.
I’m sure that Teradata Aster will evolve more towards self-service as it advances, but right now it’s a powerful tool that does a very interesting job while still requiring heavy IT involvement. That doesn’t make it bad, it just means that the technology still needs to evolve.
I studied NLP almost 30 years ago, when working with expert systems. Both hardware and software have moved forward, thankfully, a great distance since those days. The ability to leverage NLP to more quickly and accurately to understand the market, improve customer acquisition and retention ROI and better run business is a wonderful thing.
The presentation was powerful and clear, Teradata Aster provides some great benefits. It is still early in its lifecycle and, if the company continues on the current course, will only get better. They have only a few customers for the on-site optimization use, none referenceable in the demo, but there is a clear ROI message building. Mid- to large-size enterprises looking to optimize their customer understand, whether for on-site search or other modern business intelligence uses, should talk to Teradata and see if Aster fits their needs.
Yesterday I listened to a webinar by MapR and Skytree supposedly on Hadoop and machine learning. As someone with a background in artificial intelligence (from way back in the 1980s…), I was interested in the topic title. However, to be very sadly blunt, I came away not having learned anything.
There seemed to be two major problems:
1) They didn’t know who was their target audience.
2) They don’t know presentations.
I couldn’t tell if they were focused on a technical or business audience. After all, they didn’t start the presentation by explaining either predictive analytics or machine learning. The MapR guy who opened mentioned he was going to describe machine learning and then only showed a table showing how machine learning can be used in multiple use cases. The table did didn’t differ between historical and predictive analytics nor did it emphasize predictive analysis. However, he talked about MapR as if everyone should understand what it is and how it works, so that might have been aimed at a technical audience but without technical details.
After a bit more blather, he turned the presentation over to the Skytree presenter who opened with the statement that the company exists to “translate big data into actionable intelligence.” That is some differentiator…
While he also failed to give a good explanation for machine learning and how it differs from any other type of analytics, he at least had one good slide about his company’s focus.
Skytree for High-Value Problems
How they’re going to do that and how they’re different than their competitors? Well, as the old statement from textbooks says, that’s an exercise left to the student.
The entire webinar failed and I, being the humble sort I am, know why. It was not vaguely technical enough for a technical audience nor specific enough for a business audience. They never clearly differentiated their products, sticking to very generic messages. That’s often a clear symptom of something missing from companies: Product marketing.
What they had was one technical guy from MapR and one supposedly marcom guy from Skytree, neither of whom understood how to position a solution in clear terms. The key job of product marketing is inherent in the two halves of the name, understand product and create accurate messages for the market. Unfortunately, smaller companies have founders working closely with development and sales, using marketing just to create basic collateral and presentations.
There doesn’t seem to be someone who knows the market the companies were really trying to hit or how to explain their differentiators to that market. That’s why the presentation spent lots of time on platitudes and almost none of a focused message to communicate differentiators.
There may be a good solution hidden in the partnership, but this presentation did nothing to show it.