My latest article can be found here: http://searchbusinessanalytics.techtarget.com/feature/Business-intelligence-in-the-cloud-gives-boost-to-BI-process.
BI in the Cloud: Article on TechTarget
Leave a reply
My latest article can be found here: http://searchbusinessanalytics.techtarget.com/feature/Business-intelligence-in-the-cloud-gives-boost-to-BI-process.
Teradata’s recent presentation at the BBBT was very interesting. The focus, no surprise, was on Teradata Aster, but Chris Twogood, VP Products and Services Marketing, and John Thuma, Director of Aster Strategy and Analytics, took a very different approach than was taken a year earlier.
Chris Twogood started the talk with the usual business overview. Specific time was spent on four recent product announcements. The most interesting announcement was about their support for Presto, a SQL-on-Hadoop project. They are the first company to provide commercial support for the open source technology. As Chris pointed out, he counted “13 different SQL-on-Hadoop variants.” Because of the importance of SQL access and the perceived power of Presto, Teradata has committed to strengthening its presence with that offering. SQL is still the language for data access and integrating Hadoop into the rest of the information ecosystem is a necessary move for any company serving any business information market. This helps Teradata present a leadership image.
Discussion then turned to the evolution of data volumes and analytics capabilities. Mr. Twogood has a great vision of that history, but the graphic needs serious work. I won’t copy it because the slide was far too busy. The main point, however, was the link between data volumes and sources with the added capabilities to look at business in a more holistic way. It’s something many people are discussing but he seems to have a much better handle on it than most others who talk to the point, he just needs to fine tune the presentation.
As most people have seen, the much of the new data coming in under the big data rubric is customer data from sources such as the web, call logs and more. Being able to create a more unified view of the customer matters. Chris Twogood wrapped up his presentation by referring to a McKinsey & Co. survey that pointed out, among other things, that studying customer journeys can increase predictive accuracy of customer satisfaction and churn by 30-40%. Though it also points out that 56% of customer interactions are through multi-channel means, one of the key areas of focus today is the journey through a web site.
With that lead-in, John Thuma took over to talk about Aster and how it can help with on-site search. He began by stating that 25-30% of web site visitors using search leave the site if the wanted result isn’t in first three items returned, while 75% abandon if the result isn’t on first page. Therefore it’s important to have searches that understand not only the terms that the prospective customer enters but possible meanings and alternatives. John picked a very simple and clear example, depending on the part of the country, somebody might search on crock pot, slow cooker or pressure cooker but all should return the same result.
While Mr. Thuma’s presentation talked about machine learning in general, and did cover some of the other issues, the main focus of that example is Natural Language Processing (NLP). We need to understand more than the syntax of the sentence, but also improve our ability to comprehend semantic meaning. The demonstration showed some wonderful capabilities of Aster in the area of NLP to improve search capabilities.
One feature is what Teradata is calling “apps,” a term that confuses them with mobile apps, a problematic marketing decision. They are full blown applications that include powerful capabilities, applications customization and very nice analytics. Most importantly, John clearly points out that Aster is complex and that professional services are almost always required to take full advantage of the Aster capabilities. I think that “app” does a disservice to the capabilities of both Aster and Teradata.
One side bar about technical folks not really understanding business came from one analyst attending the presentation who suggested that ““In some ways it would be nice to teach the searchers what words are better than others.” No, that’s not customer service. It’s up to the company to understand which words searchers mean and to use NLP to come up with a real result.
A final nit was that the term “self-service” was used while also talking about the requirement for both professional services from Teradata and a need for a mythical data scientist. You can’t, as they claimed, used Aster to avoid the standard delays from IT for new reports when the application process is very complex. Yes, afterwards you can use some of the apps like you would a visualization tool which allows the business user to do basic investigation on her own, but that’s a very limited view of self-service.
I’m sure that Teradata Aster will evolve more towards self-service as it advances, but right now it’s a powerful tool that does a very interesting job while still requiring heavy IT involvement. That doesn’t make it bad, it just means that the technology still needs to evolve.
I studied NLP almost 30 years ago, when working with expert systems. Both hardware and software have moved forward, thankfully, a great distance since those days. The ability to leverage NLP to more quickly and accurately to understand the market, improve customer acquisition and retention ROI and better run business is a wonderful thing.
The presentation was powerful and clear, Teradata Aster provides some great benefits. It is still early in its lifecycle and, if the company continues on the current course, will only get better. They have only a few customers for the on-site optimization use, none referenceable in the demo, but there is a clear ROI message building. Mid- to large-size enterprises looking to optimize their customer understand, whether for on-site search or other modern business intelligence uses, should talk to Teradata and see if Aster fits their needs.
Looker held a webinar today. I recently blogged about their presentation to the BBBT community, but it’s an interesting company so was worth another visit. The company is a business intelligence (BI) firm. With the presenters being Colin Zima and Zach Taylor, the presentation stayed at a much higher level than the previous presentation and was aimed at a business audience rather than analysts. It is always good to see a different view of things.
The focus of their presentation is why it’s good to embed BI in other applications in opposition to pure BI tools. It’s a good message but needs to be strengthened. Colin and Zach quickly mentioned embedding as if everyone understood it, then dove into the issues in evaluation the build v buy decision. They should have spent a couple of minutes explaining what they mean by embedding and their focus on what they focus on as places to be embedded into.
Their build v buy decision discussion was standard and hit all the right points about letting companies focus on their competencies and leverage the BI industry’s competencies for analysis. Where embedding and build v buy really blend, and they could have hit harder, is the difference in ROI between embedding and having a separate BI visualization tool.
They did have a couple of case studies that were interesting. Ibotta is a company providing analytics to their consumer packages goods clients. That’s a great application and a powerful use of BI in a business network, but I didn’t see much on what it was embedded into or how. That meant it didn’t fit into the overall scheme of the presentation.
The other key one was HubSpot using Looker to provide analytics to sales on sales performance. That’s done by embedding the analytics directly into the normal Saleforce.com windows the sales team see every day. That’s a powerful message and one that I felt deserved a bit more time.
The only questionable message I heard was during Q&A, when somebody asked about their performance issues. As in the previous presentation, they talked about using the source data and not replicating for BI. They therefore said they didn’t have performance issues when scaling users but it was one for the databases. Well, that’s not quite true.
It’s not likely that all a company’s various data sources have been built to scale to lots of users. Companies will still use ODS’s, data warehouses and other methods to parallel data and have multiple versions of the truth which require strong compliance to control. Companies will still have to spend time to analyze and prepare appropriate data sources that can handle large numbers of concurrent users. The advantage of Looker is not that it means that you don’t have to add to the confusion to get performance, whatever is provided to get good performance for Looker isn’t unique and limited to it but can serve other applications as well.
Looker is that rare young company that seems to not only have a good early generation product, but understands how to market their product to multiple audiences. As someone focused on software marketing, I think that’s great.
Last Friday’s presenters to the BBBT were Satyen Sangani, CEO, and Anand Aidasani, Customer Development Lead, from Alation. The company is a two and a half year old startup that released its first product in March – a tool to help analysts better understand the metadata surrounding their corporate data.
One of the early and powerful statements by Mr. Sangini was that big data is more than volume and had a lot to do with the variety of data. I’ve talked about that before, so it is good to see more vendors openly admitting the fact. One caveat: They quickly JDBC, and move on. There was no mention about breadth of data accessed by their existing clients or any performance issues. When you talk with them, make sure to ask specific questions about your data sources.
You won’t be surprised when I now turn to their marketing message. They present a top level message of making it easier for business knowledge workers to get the information they need, but the product is all about the data analyst. While helping the later group does indirectly help the former, the message needs to be more focused on the analysts but with a split message about how they can both do their jobs faster and help their business clients respond more quickly with more accurate information.
They had a good ROI message for analysts, presented in the following slide.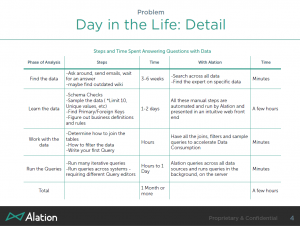
That has a lot of good content but needs to be simplified and clarified to fit into sales and marketing messages focused at IT, analysts and end users – the challenge of true enterprise positioning.
Their best strategic slide was the one where they present their platform with the high level goals of the firm.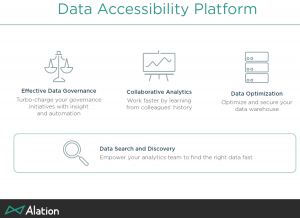
Data governance. I’ve come back to it regularly, and it matters. Even a year ago, many business intelligence startups were crowing about ignoring IT and letting users do what they want. Enterprise customers have pushed back and the smart folks have listened. Modern BI needs to be about getter better data to business people faster while still ensuring that the information matches company, contractual and regulatory governance issues. That Alation lists governance first shows a strong understanding of market needs.
Alation’s collaboration is early and, again, focused primarily on analysts and other technical people. There are some great features to see SQL being used throughout the organization and analytics about the usage. What can be shared to business users who aren’t gurus needs to be improved, but it’s a young company and the collaboration they have is a great start in helping understand data as a team to speed development and improve governance.
Their platform doesn’t directly optimize queries, but there are some nice analytics available. Just as importantly, when the software identifies either an inefficient query or one that might be slow do to a large result set, a warning can be displayed to the analyst before the query is run. It’s another first generation feature that’s nice but could use more power and breadth combined, from what I could see in a short demo, a better user interface.
The biggest challenge for Alation is not technology, it’s marketing. What are they? They’re not an ETL tool, a pure metadata application, or a BI product. They overlap a few areas but I’m not sure where they’d be categorized by all the analyst first that feel they must categorize everything. More importantly, if the Alation management can’t figure out how to message a clear message to the market, it’s going to significantly slow the sales cycle.
My view is that they are primarily a metadata tool, but a number of BBBT members expressed dismay at the mention of metadata. The pushback was the business customers don’t understand metadata. The issue I have with that argument is that it’s an IT/analyst product and they understand metadata. For the business users who are involved in the purchase decision, Alation can certainly create content that focuses on the benefits the product brings to them, which can avoid talking about metadata, but there’s no need to avoid the word in the core content focused at their primarily technical audience.
Alation seems to be a good new tool for understand where you data is coming from to improve data governance and performance. The brief time we had didn’t get me much further than that. If you’re in need of better understanding your complex information infrastructure, spend some time with them and see what they have to offer.
My latest article published in Search Data Management.
http://searchdatamanagement.techtarget.com/feature/Database-schemas-still-needed-despite-Hadoop-and-NoSQL-pretensions
Tuesday’s TDWI webinar had a guest star: Claudia Imhoff. The topic was predictive analytics and the presentation was sponsored by SAP, so Pierre Leroux, Director of Product Marketing, SAP, also had his moment towards the end. Though the title was about predictive analytics, it’s best to view the presentation as an overview of the state of analytics, and there’s much more to discuss on that.
The key points revolved around a descriptive slide Ms. Imhoff presented to describe the changing analytics landscape.
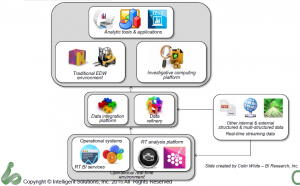
Claudia Imhoff described the established EDW information supply chain as being the left half of the diagram while the newer information, with web, internet of things (IOT) and other massive data sources adding the right hand side. It’s a nice, clean way of looking at things and makes clear that the newer data can still drive rather than eliminate the EDW.
One thing I’d say is missing is a good name for the middle box. Many folks call was Ms. Imhoff terms the Date Refinery a Data Lake or other similar rationalizations. My issue is that there’s really no need to list the two parts separate. In fact, there’s a need to have them seamlessly accessible as a whole, hence the growth of SQL for Hadoop and other solutions. As I’ve expressed before, the combination of the data integration and data refinery displayed are just the next generation of the ODS. I like the data refinery label, but think it more accurately applies to the full set of data described in the middle section of the diagram.
Claudia also described, the four types of analytics:
It’s important to understand the difference in analysis because each type of report needs to have a focus and an audience. One nit I have with her discussion of these was the comment that descriptive analytics are the least valuable. Rather, they’re the least strategic. If we don’t know what happened, we can’t feed the other types of analytics, plus, reporting requirements in so much of business means that understanding and reporting what happened remains very valuable. The difference is not how valuable, but in what way. Predictive and prescriptive analytics can be more valuable in the long term, but their foundation still resides on descriptive.
My biggest complaint with our industry at large is still the obsession with the mythical data scientist. Claudia Imhoff spent a good amount of time on the subject. It’s a concept with super human requirements, with Claudia even saying that the data scientist might be the one with deep business knowledge. Nope. Not going to happen.
In Q&A, somebody brought up the point I always mention: Why does it have to be one person rather than a team. Both Claudia Imhoff and Pierre Leroux admitted that was more likely. I wish folks would start with that as it’s reasonable and logical.
I was a programmer as folks began calling themselves software engineers. I never liked that. The job wasn’t engineering but a blend of engineering and crafting. There was art. The two presenters continued to talk about the data scientist as having an art component, but still think that means the magical person is still a scientist. In addition, thirty year ago the developer was distanced much further from business, by development methods, technology and business practice. Being closer means, again, teamwork, with each person sharing expertise in math, coding, business and more to create a robust solution.
That wall has been coming down for years, but both technology and business are changing rapidly and are far more complex. The team notion is far more logical.
The other major problem I had was a later slide and words accompanying it that implied it’s up to the business people to get on board with what the technologists are doing. They must find the training, they must learn that analytics are the answer to everything.
Yes, we’re able to provide better analytics faster to management than in the past. However, they’re not yet perfect nor will they be. Models are just that. As Pierre pointed out, models will never explain 100%.
Claudia made a great point earlier about one of the benefits of big data is to eliminate sampling and look at what the entire market is doing, but markets are still complex and we can’t glean everything. Technologists must get of the high horse and realize that some of the pushback from management is because the techies too often tend to dismiss intuition and experience. What needs to happen is for the messages to change to make it clear that modern analytics will help executives and line management make better decisions, not that it will replace their decision making.
In addition, quit making overly complex visualization that have great scientific relevance but waste time. The users do not need to understand the complexities of systems. If we’re so darned smart, we can distill the visualizations to things easier to comprehend so that managers can get the information, add it to all the other information and experience and make decision.
Technologists must adapt to how business runs as much as business must adapt to leverage technology.
The title of the presentation misrepresents the content. It was a very good presentation for understanding the high level landscape of the analytics information supply chain and it’s a discussion that needs to be held more often.
You’ll notice I didn’t say much about the demo by Pierre Leroux. That’s because of technical issues between demo and webinar software. However, both he and Claudia Imhoff took questions about the industry and market and gave thoughtful answers that should help drive the conversation forward.
Yesterday’s TDWI webinar was sponsored by Liaison Technologies, who did the same thing last year. It’s a push for another acronym. While the acronym isn’t needed, the concept is. Data Platform as a Service is just using the cloud to help with data integration. Gosh, complex, ‘eh? I think it’s the natural progression of technology and business, it’s just data management on the cloud. But forget the marketing, let’s talk about the concept.
The presentation’s first half was delivered by Phillip Russom. He started with some very trivial level setting but then quickly got to a key point. If you’ve been around for a while, you remember Best of Breed. That’s when each vendor focused product company, somewhere in the information supply chain, talked about their openness and how you could piece together a solution from different vendors. That made sense at the time, since many companies were each creating the early version of parts of a full solution.
As Phillip pointed out, times have changed. We now better understand business needs, have learned more about coding the requirements and can access far better hardware than we had fifteen years ago. That means IT is looking for what they couldn’t find back then: An integrated solution from a single or a far more limited number of vendors. They want something simpler than a hodgepodge of multiple systems.
The advantages of the cloud aren’t specific to data management. One very key business driver that was minimized in Mr. Russom’s presentation but brought out later by Patrick Adamiak during his presentation then revisited by both in the Q&A is capex versus opex – something often ignored by technical folks. Having your own hardware and data center is not just costly, it’s part of capital expenditure. Service contracts with a cloud vendor are operational expenses. That means the CxO suite and Board are often happier with that because it’s not as locked it and creates flexibility in the corporate financial picture.
One nit I had with Mr. Russom’s presentation was his statement that cloud is another architecture, like client/server or the web. The cloud and web are client server, that’s not the issue. It’s another architecture in two other key aspects: The already mentioned capex/opex divide, and the way it changes a software vendor’s ability to manage and update their software in comparison to on-premises installations.
One caution he gave that needed more explanation for folks new to the cloud was when Mr. Russom mentioned that you need to ask about the elasticity of the cloud implementation. For those who might not have heard the term, elasticity is the ability to grow or shrink cloud resources in order to match processing demands. In other words, if you get a big data dump from another source, can you quickly access more disk space? Or, from the Web side of the house: You’re hosting a big event or making a major announcement on your Web site: Can site resources be replicated quickly to handle the additional load then released when no longer needed?
I was impressed by the fact that capex was mentioned on Patrick Adamiak’s first slide. Cloud technology has multiple advantages that can be communicated to IT, but it’s the capex/opex issue that will help close the deal in an enterprise setting. Liaison seems to understand the need to blend technical and business messages.
However, most of Mr. Adamiak’s presentation seemed to be about justifying the new acronym. The main slide compared dPaaS with other supposed solutions without admitting there’s really a lot of overlap between them. The columns weren’t as different as he’d like them to be.
His company slides didn’t seem any different than those I’ve seen from the many other firms in the space. Forget all of that, it was in a short webinar with TDWI, so he had limited time.
The fact is that Liaison claims they are where the market is going. They are vertically integrating the information supply chain while leveraging the cloud for its business and technology advantages. For those in IT looking to simplify their world, Liaison is a company that should be investigated.
The most recent BBBT presentation was from Dell Software. Peter Evans, Sr. Integrated Solutions Development Consultant , and Steven Phillips, Product Marketing Manager – Big Data & Analytics, gave us an overview of Dell’s architecture for addressing business intelligence (BI). 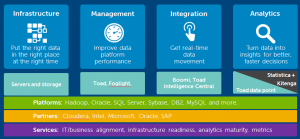
What they’re working to accomplish is, no surprise, ensure that Dell’s hardware is able to be present throughout the BI supply chain. For that, they’re working to be application agnostic, though they mislabel it as “no lock-in.” What they’re saying is you can change your software vendors and Dell will still be there. There’s no addressing true lock-in, the difficulty in changing one software vendor to another based on level of openness to data in systems and other costs of moving.
One marketing nit that caught a number of us was Peter’s early claim that Dell is “probably the third largest software company in the world.” Right… First, as a now privately held company, we have no way to confirm that. Second, I’m not sure if he knows just how much revenue is needed to be near the top of that list.
Far too many young firms are overselling BI as something that will let business “avoid IT.” That’s not only impossible, it wouldn’t make sense if it was possible. IT has a clear place in organizing infrastructure, providing consistency, helping with compliance and doing other things a central organization should do.
Dell has started with IT. They’re used to dealing with IT and their solution is focused on helping IT enable business. What’s not clear is how well they can do such a thing in the new world. They’ve pieced a lot of different applications into an architecture and that would seem to require heavy IT involvement in much of what’s being provided.
On the good side, that knowledge means they better understand true enterprise business needs. Unlike many vendors, Dell has regulatory and statutory compliance at the forefront, very clear in its marketechture slides. While most companies understand they have to mention compliance, it’s usually people dealing with corporate business groups such as IT and legal who understand just how critical compliance is.
Neither Peter Evans nor Steven Phillips spoke clearly to the business user, the want for speed and flexibility for them. While younger companies need to move more to addressing the importance of IT, Dell needs to more strongly focus on the business customer, the ones who are often in charge of the BI and related software projects and spending.
The technical piece that stuck with me the most was the discussion of Boomi Suggest. Boomi is Dells integration tool. Within it, there’s a cloud-based tool called Boomi Suggest. If users subscribe to it, the product tracks data linkages and the de-natured information is kept to help other customers more quickly map data sources and targets.
Mr. Evens says that Boomi Suggest has a database that now contains more than 16 million links. The intelligence on top to that then is able to provide a 92% accuracy rate in analyzing new links. The time savings that alone suggests is a major decision driver that should not be overlooked.
While the case study didn’t address enough of the end user issues of timeliness, flexibility and more, it was a very interesting case study from an inclusive standpoint. The Dell team focused on asthma case management to show the breadth of data sources, the complexity of analytics and a full process that could be generalized from the healthcare sector in order to support their full platform message.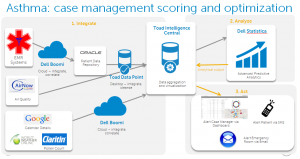
As you can see, they are doing a lot of things with a variety of information, but they’re also doing it with a variety of products.
Dell’s decades of working with IT has helped it look at BI with a more complex eye that can address many of IT’s concerns. What we saw was an almost completely IT solution and message. While BI focused companies are going to have to move down and address important IT messages, Dell must go in the opposite direction. Unless the team can broaden their message to address the solution to more business teams, Dell’s expansion in the market will be severely limited because it’s the business groups that write the checks.
The presentation shows a great start. However, the questions are if Dell can simplify the architecture to make it less complex, potentially by merging a number of their products, and whether or not they can learn about those folks they don’t have a history of directly understanding: The business user. If they can do that, the start will expand and Dell Software can help in the BI market.
The most recent BBBT presentation was by Looker. Lloyd Tabb, Founder & CTO, and Zach Taylor, Product Marketing Manager, showed up to display yet another young company’s interesting technology.
Looker’s technology is an application server that sits above relational databases to provide faster, more complex queries. They’ve developed their own language, LookML to help with that. That’s no surprise, as Lloyd is a self-described language guy.
It’s also no surprise that the demos, driven by both Lloyd and Zach, were very coding heavy. Part of the reason that very technical focus exists is, as Mr. Tabb stated, that Looker thinks there are two groups of users: Coders who build models and business managers who use the information. There is no room in that model for the business analyst, the person who understands who to communicate a complex business need to the coders and how to help the coders deliver something that is accessible to and understandable by the information consumer.
How the bifurcation was played out in the demonstration was through an almost exclusive focus on code, code and more code, with a brief display of some visualization technology. The former was very good while the later wasn’t bad but, to fit with their mainly technology focus, had complex visualizations without good enough legends – they were visualizations that would be understood by technical people but need to be better explained for the business audience they claim to address.
As an early stage company, that’s ok. The business intelligence (BI) market is still young and very fragmented. You can get different groups in large companies using different BI tools. While Looker talks about 300 customers, as with most companies of their size it could only be those small groups. If they’re going to grow past those groups, they need to focus a bit more in how to better bridge technology and business.
They also have a good start in attracting the larger market because they support both cloud and on-premises systems. The former market is growing while the later isn’t going away. Providing the ability for their server to run either place will address the needs of companies on either side of the divide.
One key to their system is they don’t move data. It stays resident on the source systems. Those could be operational systems, data warehouses, an ODS or whatever. What they must have is SQL. When asked about Hadoop and other schema-on-write systems, the Looker team stated they are an RDMS based application but they’ll work on anything with SQL access. I have no problem with the technology, but they need to be very clear about the split.
SQL came from the relational world, but as they pointed out in an aside, it isn’t limited to that. They should drop the RDMS message and focus on SQL. As Lloyd Tabb said, “SQL is the right abstraction.” What I don’t know if he understands, being focused on technology and having those biases, is it isn’t the right abstraction because of some technical advantage but because it’s the major player. McDonalds isn’t the best burger because it has the most stores. SQL might not be the best access method, but it’s the one business knows and so it’s the one the newer database companies and structures can’t ignore.
Last year, the BBBT heard from multiple companies including Actian and EXASOL, companies focused on providing SQL access to Hadoop. That’s as important as what Looker is doing. The company that manages to do both well with jump ahead of the pack.
Looker is a good, young company with some technical advantages that can greatly improve the performance of SQL queries to business databases and provides a basic BI front end to display the results. I’m not sure they have the resources to focus on both, and I think the former have the clearest advantage in the marketplace. Unless they have more funding and a strong management team that can begin to better understand the business side of the market, they will have problems addressing the visualization side of BI. They need to keep improving their engine, spread it to access more data sources, and partner with visualization companies to provide the front end.
Tuesday saw a rare, mid-week presentation at the BBBT. Silwood Technology, an Ascot, UK, company sent people to Boulder to present their technology. Roland Bullivant, Sales and Marketing Director, and Nick Porter, Technical Director (and a co-founder) were the presenters.
Silwood Safyr is focused on helping IT understand the metadata in their major packaged enterprise systems, primarily from SAP and Oracle with a recent addition of Salesforce. As those familiar with the enterprise application space know, there are a lot of tables in SAP and Oracle and documentation has never been, shall we say, close to perfect. In addition, all customers of those systems customize the applications, thereby making the metadata more difficult to understand. Safyr does a very good job at finding the technical metadata.
Let me make that clear: Technical metadata. The tables, indices and their relations are what is found. That’s extremely valuable, but not the full picture. Business metadata is not managed. I’ll discuss that in more detail below.
The company, as expected from European companies, uses partners rather than direct sales for its primary sales channel. In addition, they OEM white label products through IBM, CA and other firms. All told, Roland Bullivant says that 70% of their customers are via reseller channels. Also as expected, they still remain backline support for those partners.
As mentioned above, Safyr captures the database structure metadata. As Roland so succinctly put it, “The older packages weren’t really built with the outside world in mind.” The internal structures aren’t pretty and often aren’t easily accessible. However, that’s not the only difficulty in understanding an enterprise’s data structures.
Salesforce has a much simpler data structure, intentionally created to open the information to the ecosystem of partner applications that then grew up around the application. Still, as Mr. Bullivant pointed out, there are companies in Europe that have 16 or more customized versions in different countries or divisions, so understanding and meshing those disparate systems in order to build a full enterprise data model isn’t easy. That’s where Safyr helps.
Silwood Safyr is a great leap forward from having nothing, but there’s still much missing. While they build a data model, there’s not enough intelligence. For instance, they leave it to their users to figure out which tables are production and which are duplicates or other tables used just for performance. Sure, a table with zero rows usually means either a performance table or an unlocked app segment, but that’s left for the user rather than flagging, filtering and indicating any knowledge of the application and data structures.
Also, as mentioned above, there’s no business intelligence (gosh, where’d that word come from?). There’s nothing that lets people understand the business logic of the applications. That’s why this is a pure IT tool. The structures are just described in technical terms, exported to data modeling tools (a requirement for visualization, ERwin was used in the demo but they work with others ) and then left to the analysts to identify all the information need to clarify which tables are needed for which business purpose or customer.
One way to start working on that was indicated in Nick Porter’s demo. He showed that Safyr is good at not just getting table names, but also in accessing descriptive names and other metadata about the tables. That’s information needs to be leveraged to help prepare the results for use by people on the business side of the organization.
The main hole I see in the business links from the last section: The lack of emphasis on business knowledge. For instance, there’s a comparison function to analyze metadata between databases. However, as it’s purely on a technical level, it’s limited to comparing SAP with SAP and Oracle with Oracle. Given that differences in versions of those products can be significant, I’m not even sure how well that works across major version releases.
Not only do global enterprises have multiple versions of one vendor, they have SAP on one continent, Oracle in another and might acquire a new company that is using Salesforce. That lack of an ability to link business layers means that each package is working in a void and there’s still a lot of work required to build a coherent global picture.
Another part of their growth need is my usual soapbox. When the Silwood team was talking about how they couldn’t figure out why they weren’t growing as fast as they should, Claudia Imhoff beat me to the punch. She mentioned marketing. They’d earlier pointed out they don’t spend much on marketing and she quickly pointed out that’s a problem. This isn’t Field of Dreams, they won’t come just because you build it. Silwood marketing basics are good, with a lack of visible case studies being one hole, but they’re not pushing their message out through the channels.
Silwood Safyr is a good core product to help IT automate the documentation of data models in packaged enterprise software. It’s a product that should be of interest to every large enterprise using complex applications such as those by Oracle and SAP, or even multiple versions of simple databases such as Salesforce. However, there are two things missing.
The most important missing piece in the short term is the marketing necessary to help their resellers better understand benefits both they and the end customer receive, to improve interest in reselling and to shorten sales cycles.
The second is to look long term at where they can grow the business. My suggestion is to better work with business logic within and across applications vendors. That’s the key way they’ll defend their turf against the BI vendors who are slowly moving downstream to more technical data access.
The reason people want to understand data models isn’t out of curiosity, it’s to better understand business. Silwood has a great start in aiding enterprises in improving that understanding.