Way back, in the dawn of time, there were ATT and BSD, with multiple flavors of each base type of Unix. A few years later, there were only Sun, IBM and HP. In a later era, there was this thing called Linux. Lots of folks took the core version, but then there were only Redhat and a few others.
What lessons can the Hadoop market learn from that? Mission critical software does not run on freeware. While open source lowers infrastructure costs and can, in some ways, speed feature enhancements, companies are willing to pay for knowledge, stability and support. Vendors able to wrap the core of open source up in services to provide the rest make money and speed the adoption of open-source based solutions. Mission critical applications run on services agreements.
It’s important to understand that distinction when discussing such interesting companies as Cloudera, whose team presented at last Friday’s BBBT session. The company recently received a well-publicized, enormous investment based on the promise that it can create a revenue stream for a database service based on Hadoop.
The team had a good presentation, with Alan Saldich, VP Marketing, pointing out that large, distributed processing databases are providing a change from “bringing data to compute” to “bringing compute to data.” He further defined the Enterprise Data Hub (EDH) as the data repository that is created in such an environment.
Plenty of others can blog in detail about what we heard about the technology, but I’ll give it only a high level glance. The Cloudera presenters were very open about their product being an early generation and they laid out a vision that seemed to be good. They understand their advantages are the benefits of Cloud and Hadoop (discussed a little more below) but that the Open Source community is lagging in areas such as access and control to data. It’s providing such key needs to IT that will help their adoption and provide a revenue stream, and their knowing that is a good sign.
I want to spend more time addressing the business and marketing models. Cloudera does seem to be struggling to figure out how to make money, hence the need more such a large investment from Intel. Additional proof is the internal confusion of Alan saying they don’t report revenues and then showing us only bookings, while Charles Zedlewski, VP Products, had a slide claiming they’re leading their market in revenue. Really? Then show us.
They do have one advantage, the Cloud model lends itself to a pricing model based on nodes and, as Charles pointed out, that’s a ““business model that’s inherently deflationary” for the customer. Nodes get more powerful so the customers regularly get more bang for the buck.
On the other side, I don’t know that management understands that they’re just providing a new technology, not a new data philosophy. While some parts of the presentation made clear that Cloudera doesn’t replace other data repositories except for the operational data store, different parts implied it would subsume others without giving a clear picture of how.
A very good point was the partnerships they’re making with BI vendors to help speed integration and access of their solution into the BI ecosystem.
One other confusion that Cloudera, and the market as a whole, seems to be clearly differentiating that the benefits of Hadoop come from multiple technologies: Both the software that helps better manage unstructured data and simple hardware/OS combination that comes from massively parallel processing, whether the servers are in the Cloud or inside a corporate firewall. Much as what was said about Hadoop had to do with the second issue, and so the presenters rightfully got pushback from analysts who saw that RDBMS technologies can benefit from those same things and therefore minimizing that as a differentiator.
Charles did cover an important area of both market need and Cloudera vision: Operational analytics. The ability to quickly massage and understand massive amounts of operational information to better understand processes is something that will be enhanced by the vendor’s ability to manage large datasets. The fact that they understand the importance of those analytics is a good sign for corporate vision and planning.
Open source is important, but it’s often overblown by those new to the industry or within the Open Source community. Enterprise IT knows better, as it has proved in the past. Cloudera is a the right place at the right time, with a great early product, the understanding as to many of the issues that are needed in the short term. The questions are only about the ability to execute both on the messaging and programming sides. Will their products meet the long term needs of business critical applications and will they be able to explain clearly how they can do so? If they can answer correctly, the company will join the names mentioned at the start.

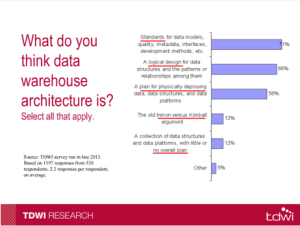 Another key point was made as to the evolving nature of the definition of data warehousing. Twenty years ago, it was about creating the repository for combining and accessing the data. That is now definition number three. The top two responses show a higher level business process and strategy in place than “just get it!”Where I have a problem with the presentation is when Mr. Russom stated that analytics are different than reporting. That’s a technical view and not a business one. His talk contained the reality that first we had to get the data, now we can move on to more in depth analysis, but he still thinks they’re very different. It’s as if there’s a wall between basic “what’s the data” and “finding out new things,” concepts he said don’t overlap. Let’s look at the current state of BI. A “report” might start with a standard layout of sales by territory. However, the Sales EVP might wish to wander the data, drilling down and slicing & dicing to understand things better by industry in territory, cities within and other metrics across territories. That combines what he defines as separate reporting and data discovery.
Another key point was made as to the evolving nature of the definition of data warehousing. Twenty years ago, it was about creating the repository for combining and accessing the data. That is now definition number three. The top two responses show a higher level business process and strategy in place than “just get it!”Where I have a problem with the presentation is when Mr. Russom stated that analytics are different than reporting. That’s a technical view and not a business one. His talk contained the reality that first we had to get the data, now we can move on to more in depth analysis, but he still thinks they’re very different. It’s as if there’s a wall between basic “what’s the data” and “finding out new things,” concepts he said don’t overlap. Let’s look at the current state of BI. A “report” might start with a standard layout of sales by territory. However, the Sales EVP might wish to wander the data, drilling down and slicing & dicing to understand things better by industry in territory, cities within and other metrics across territories. That combines what he defines as separate reporting and data discovery.