Yesterday I listened to a webinar by MapR and Skytree supposedly on Hadoop and machine learning. As someone with a background in artificial intelligence (from way back in the 1980s…), I was interested in the topic title. However, to be very sadly blunt, I came away not having learned anything.
The Presentation
There seemed to be two major problems:
1) They didn’t know who was their target audience.
2) They don’t know presentations.
I couldn’t tell if they were focused on a technical or business audience. After all, they didn’t start the presentation by explaining either predictive analytics or machine learning. The MapR guy who opened mentioned he was going to describe machine learning and then only showed a table showing how machine learning can be used in multiple use cases. The table did didn’t differ between historical and predictive analytics nor did it emphasize predictive analysis. However, he talked about MapR as if everyone should understand what it is and how it works, so that might have been aimed at a technical audience but without technical details.
After a bit more blather, he turned the presentation over to the Skytree presenter who opened with the statement that the company exists to “translate big data into actionable intelligence.” That is some differentiator…
While he also failed to give a good explanation for machine learning and how it differs from any other type of analytics, he at least had one good slide about his company’s focus.
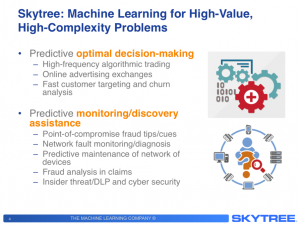
Skytree for High-Value Problems
How they’re going to do that and how they’re different than their competitors? Well, as the old statement from textbooks says, that’s an exercise left to the student.
The Need for Product Marketing
The entire webinar failed and I, being the humble sort I am, know why. It was not vaguely technical enough for a technical audience nor specific enough for a business audience. They never clearly differentiated their products, sticking to very generic messages. That’s often a clear symptom of something missing from companies: Product marketing.
What they had was one technical guy from MapR and one supposedly marcom guy from Skytree, neither of whom understood how to position a solution in clear terms. The key job of product marketing is inherent in the two halves of the name, understand product and create accurate messages for the market. Unfortunately, smaller companies have founders working closely with development and sales, using marketing just to create basic collateral and presentations.
There doesn’t seem to be someone who knows the market the companies were really trying to hit or how to explain their differentiators to that market. That’s why the presentation spent lots of time on platitudes and almost none of a focused message to communicate differentiators.
There may be a good solution hidden in the partnership, but this presentation did nothing to show it.